1. 사전 환경 구성
호스트 : pcmk1(172.31.0.10), pcmk2(172.31.0.20)
OS : CentOS 7 (AWS EC2)
사용할 가상 IP : 172.31.0.30

호스트간 통신에 필요한 포트 : TCP 2224, 3121, 5403, 21064, 9929 / UDP 5404, 5405, 9929 (보안그룹에서 open)
2. 호스트 등록 (양쪽 다)
양 쪽 호스트에서 vi /etc/hosts 로 각 호스트들을 등록해준다
172.31.0.10 pcmk1
172.31.0.20 pcmk2
172.31.0.30 vip

3. cluster package 설치 / pcs 데몬 시작 (양쪽 다)
yum install -y pacemaker corosync pcs
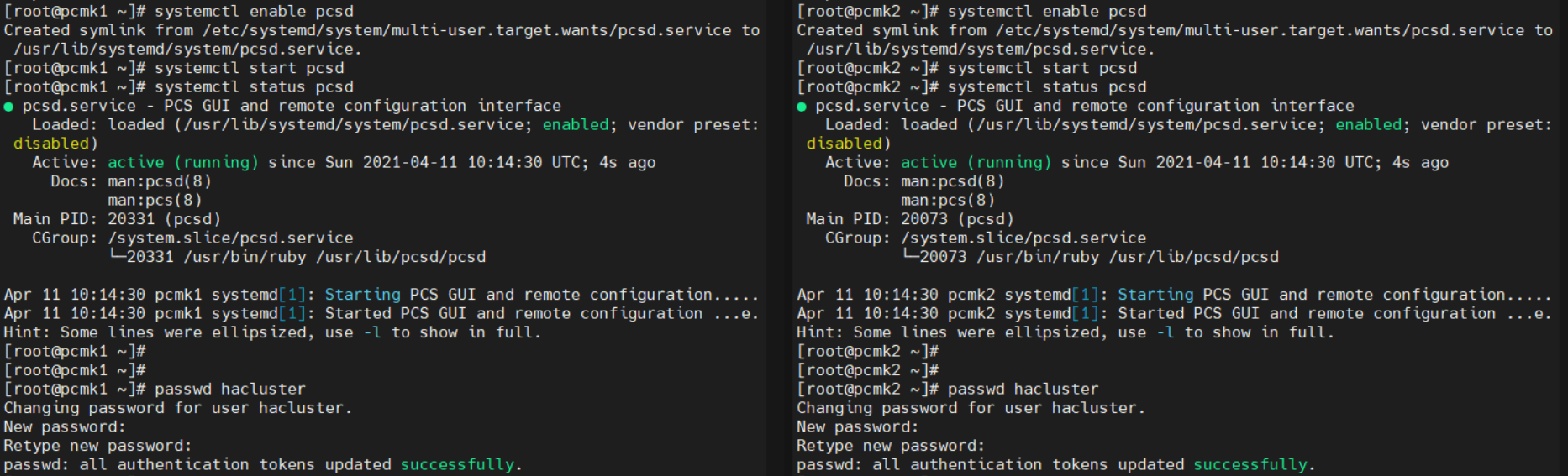
systemctl start pcsd
systemctl enable pcsd
4. 클러스터 계정 설정 (양쪽 다)
hacluster 계정은 자동으로 생성된거고, 해당 계정의 비밀번호는 양쪽 모두에서 동일하게 설정해줘야 한다
passwd hacluster
[암호 2번 입력]
5. 각 노드에 대한 hacluster 사용자 인증 (한쪽에서만 진행)
pcs cluster auth pcmk1 pcmk2
hacluster
[암호]

각 노드 간 통신이 안되면 실패할 수 있다
위에 적어놓은 통신 포트들을 열고, /etc/hosts 파일도 확인해보자
6. 클러스터 생성/실행 (한쪽만 진행)
pcs cluster setup 명령을 통해 corosync를 구성하고 다른 노드와 동기화한다
pcs cluster start 명령으로 클러스터를 실행시킬 수 있다
pcs cluster setup --name first_cluster pcmk1 pcmk2
pcs cluster start --all

7. 클러스터 확인
# 클러스터 통신 확인
corosync-cfgtool -s
# 멤버쉽과 쿼럼 확인
corosync-cmapctl | egrep -i members
# corosync / 클러스터 상태 확인
pcs status corosync
pcs status


8. STONITH 비활성화 (한쪽만)
클러스터 설정을 변경하기 전엔 crm_verify 명령을 통해 유효성을 확인해주는게 좋다고 한다
crm_verify -LV

이전 글에서도 말했지만, STONITH는 서비스가 중복으로 실행되어 충돌나는것을 방지하기 위해 오류가 발생한 호스트를 죽이는 Fencing 기능이다
cluster를 실행하면 데이터의 무결성을 확보하기 위해 기본으로 STONITH가 활성화되어있다 -> 비활성화를 해주자
pcs property set stonith-enabled=false
pcs property show

9. Active/Passive 클러스터 설정 - 가상IP 생성 (한쪽만)
가상 IP를 리소스로 추가해주자
pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=172.31.0.30 cidr_netmask=24 op monitor interval=30s

pcs status와 ip addr로 가상 IP가 잘 추가된걸 확인할 수 있다
<ocf:heartbeat:IPaddr2>는 <리소스 표준:리소스 프로바이더:리소스 스크립트 이름> 형태이다
리소스 표준에 대해선 지난 글에서 설명한 적 있다
아무튼 각 필드에 들어갈 수 있는 이름들은 아래 명령들로 확인할 수 있다
pcs resource standards
pcs resource providers
pcs resource agents ocf:heartbeat

이 중 가상 IP를 생성하는 스크립트가 IPaddr2이다
10. Failover Test
먼저 양쪽 호스트에서 pcs status로 상태를 확인해보자
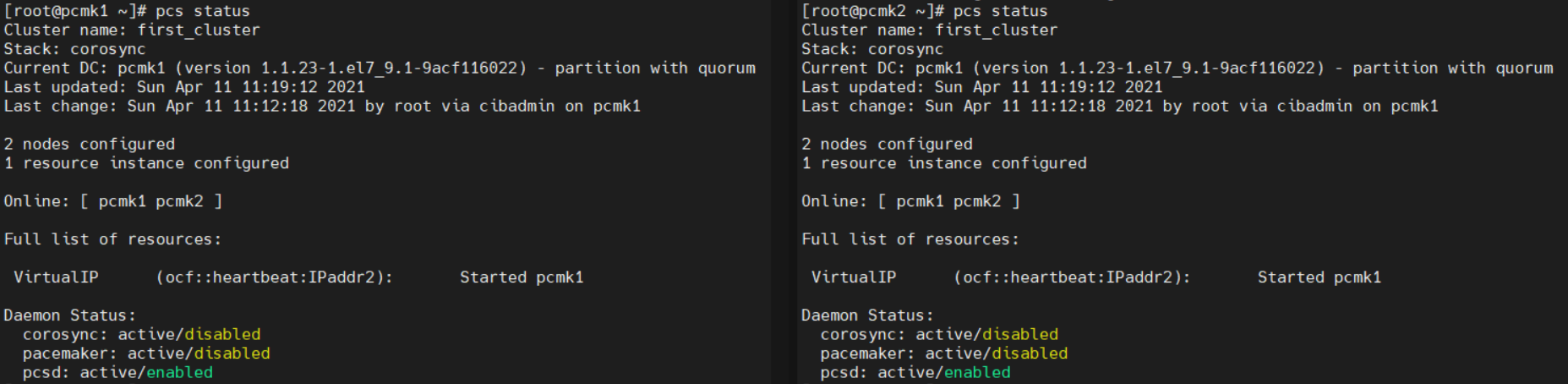
VirtualIP 리소스가 pcmk1에서 실행되고 있다
pcmk1을 정지시키면서 failover를 확인해보자 (한쪽에서만)
pcs cluster stop pcmk1pcmk2에서 상태를 확인해보면

리소스가 pcmk2로 넘어왔다
pcs cluster start pcmk1로 다시 실행해도 리소스는 다시 돌아오지 않는다

11. 클러스터 서비스로 아파치 웹서버 등록 (양쪽 다)
먼저 Apache를 설치해준다
yum install -y httpdvi /var/www/html/index.html 로 파일을 설정해준다
<h1>Hello I'm pcmk</h1>별 의미 없이 대충 만들어줬다

vi /etc/httpd/conf.d/status.conf 에 아래 내용을 입력해준다
<Location /server-status>
SetHandler server-status
Require local
</Location>

이제 웹서비스 리소스를 등록해주자 (한쪽만)
pcs resource create WebService ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://localhost/server-status" op monitor interval=1min
12. 리소스 통합 (한쪽만)
pcs status를 실행해보면

VirtualIP와 WebService가 각각 다른 호스트에서 돌고있다
이 둘을 묶어줄건데, 리소스에 대한 설정은 pcs constraint를 사용하면 된다
pcs constraint colocation add WebService with VirtualIP INFINITYINFINITY는 우선순위에 대한 점수를 무한으로 준 것이다
다시 pcs status를 해보면
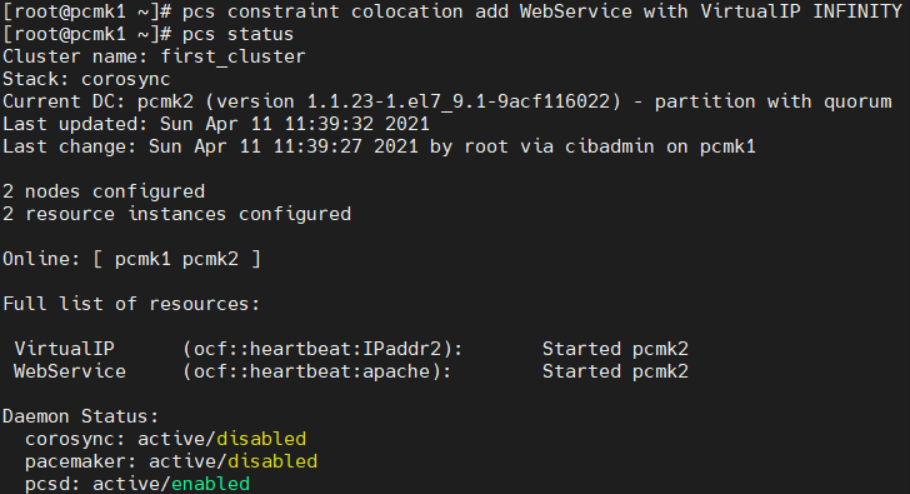
둘이 같이 pcmk2에서 돌고있다
13. 리소스 이동 (한쪽만)
만약 두 노드 중 하나에게 더 큰 우선순위를 지정하고 싶으면 constraint location을 사용하면 된다
pcs constraint location WebService prefers pcmk1=50

pcs constraint만 실행하면 현재 적용중인 constriant들을 볼 수 있다
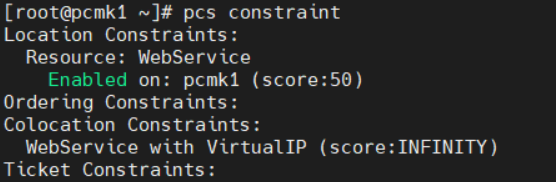
pcs constraint --full 을 실행하면 constraint의 id를 확인할 수 있고, 이를 사용해서 remove도 할 수 있다
pcs constraint --full
pcs constraint remove <id>

출처
이 설치 가이드는 RHEL 8.X, CentOS 8.X, Rocky Linux 8.4 GA에서 모두 테스트 완료된 가이드입니다.
아래의 가이드는 레드햇 공식 문서와 Serverworld 사이트를 참고하여 테스트하였습니다.
CentOS 8 : Pacemaker : Install : Server World
# authorize among nodes [root@node01 ~]# pcs host auth node01.srv.world node02.srv.world Username: hacluster Password: node01.srv.world: Authorized node02.srv.world: Authorized # configure cluster [root@node01 ~]# pcs cluster setup ha_cluster node01.srv.wo
www.server-world.info
Chapter 2. Getting started with Pacemaker Red Hat Enterprise Linux 8 | Red Hat Customer Portal
Access Red Hat’s knowledge, guidance, and support through your subscription.
access.redhat.com
☞ Pacemaker RPM 설치
# dnf install pcs pacemaker fence-agents-all
# systemctl enable --now pcsd
☞ 클러스터 계정 존재여부
# cat /etc/passwd |grep hacluster
# passwd hacluster
☞ HB 등 별칭 등록
# vi /etc/hosts
#### Default IP ####
111.222.333.241 lilo-ha1
111.222.333.242 lilo-ha2
#### Pacemaker Hearbeat IP ####
11.2.333.246 lilo-hb1
11.2.333.247 lilo-hb2
☞ 클러스터 호스트 인증
서로 통신하려면 서로를 알아야 됨, 클러스터 계정을 통해 알아야 되기 때문에 "hacluster" 계정 이용
# pcs host auth lilo-hb1 lilo-hb2
Username: hacluster
Password:
lilo-hb1: Authorized
lilo-hb2: Authorized
☞ 클러스터 구성 및 구성원 등록
RedHat 벤더사는 Cluster Name이나 Node Name을 대문자가 아닌 소문자를 사용하는 것을 권장함.
(권장이지 필수는 아니기 때문에 어느 것을 선택해도 무관함)
# pcs cluster setup lilo-cluster --start lilo-hb1
# pcs cluster setup lilo-cluster --start lilo-hb2
☞ 클러스터 구성 및 구성원 확인
# pcs cluster status
Node List:
* Online: [ lilo-hb1 lilo-hb2 ]
PCSD Status:
lilo-hb1: Online
lilo-hb2: Online# pcs status
Cluster name: lilo-cluster
Cluster Summary:
* Stack: corosync
* Current DC: lilo-hb2 (version 2.0.5-9.el8.1-ba59be7122) - partition with quorum
* Last updated: Sat Jun 19 22:39:30 2021
* Last change: Fri Jun 18 10:59:20 2021 by root via cibadmin on lilo-hb1
* 2 nodes configured
* 0 resource instances configured
Node List:
* Online: [ lilo-hb1 lilo-hb2 ]
Full List of Resources:
* No resources
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
☞ 클러스터 펜싱 비활성화
# pcs property set stonith-enabled=false
☞ Corosync 설정 업데이트
※ 노드 간 토큰 손실 선언을 기다리는 시간은 10초이고 가입 참여 요청 메세지를 기다리는 시간은 0.1초로 설정
※ 네트워크 MTU 변경 사항을 찾기 위해 knet PMTUd가 실행되는 빈도는 35, MTU는 네트워크 통신 중 최대 패킷의 크기
※ 적용시 참고 자료
How to change totem token timeout value in a RHEL 5, 6, 7, 8 or 9 High Availability cluster? - Red Hat Customer Portal
I have a Red Hat Enterprise Linux cluster using the default token timeout value of 10 seconds. I want to increase this value to make the cluster more resilient against unresponsive nodes, network interruptions, or similar delays. I need to modify the clust
access.redhat.com
☞ 레드햇 답변 중 토큰 관련 자료
totem token노드가 토큰이 손실 된 것으로 간주 할 때까지의 시간 (밀리 초)이며,이 시점에서 어떤 노드가 여전히 응답하고 있는지, 멤버로 남아 있어야하고 어떤 노드가 누락되고 제거되어야하는지 결정하는 절차를 시작함
기본적으로 이 설정은 클러스터에서 노드를 제거하기위한 조치를 취하기 전에 노드가 응답하지 못할 수있는 시간을 제어함
아래의 토큰 관련 설정은 네트워크 환경에 따라 다르기 때문에 초기 구축시에는 설정하지 않는 것이 좋습니다.
관련 이슈가 발생하면 적용하는 방향으로 고려하는 것이 좋아보입니다.
# pcs cluster config update transport knet_pmtud_interval=35 totem token=10000 join=100# pcs cluster config
Cluster Name: lilo-cluster
Transport: knet
Nodes:
lilo-hb1:
Link 0 address: lilo-hb1
nodeid: 1
lilo-hb2:
Link 0 address: lilo-hb2
nodeid: 2
Transport Options:
knet_pmtud_interval: 35
Crypto Options:
cipher: aes256
hash: sha256
Totem Options:
join: 100
token: 10000
☞ VIP 등록전 구성도 파악하기
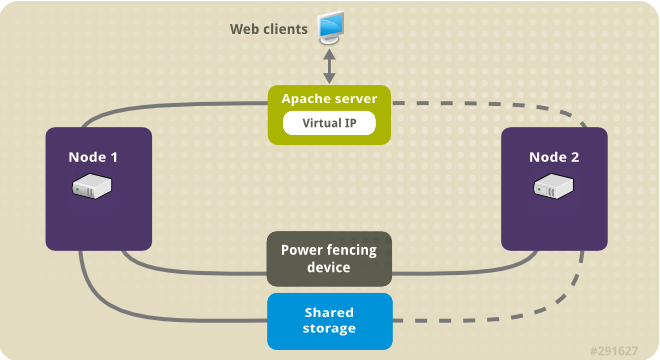
- Shared Storage: 공유 스토리지를 의미하며 양쪽 노드가 같이 사용할 수 있는 공간임, 주로 iSCSI, Fibre Channel를 이용한 블록 장치
- Power Fencing Device: Fecning 역할을 하는 Device
Fecing은 Management Port를 통해 서버를 원격지에서 관리할 수 있는 HP의 iLo, IBM의 IMM 등으로 구성할 수 있음 (fence_ipmilan)
※ Management 뿐만 아니라 Storage 혹은 Disk로도 구성이 가능 (SBD_Device, SCSI)
※ Hypervisor에서도 Management 계정을 통해 설정이 가능
※ Fencing: 장애가 발생한 노드나 리소스를 비활성화 시키는 기능
- Virtual IP: 온보드의 포트나 NIC 포트에서 직접적으로 할당된 IP는 아니지만 유동적인 서비스에서 유용하게 쓰임
주로 2개 이상의 서버에서 Active/Standby 구조에서 해당 서버들의 대표 IP로 많이 쓰임
☞ VIP 리소스 생성 전 리소스 고착성 유지
고착성 수치를 1000으로 설정해서 다른 노드로 리소스가 넘어가지 않게 해줌
해당 작업은 Pacemaker의 원천인 Clusterlabs에서도 권장하는 내용 중 하나임
※ DB와 같은 서비스의 경우는 재기동 시간이 상당히 길 수도 있기 때문에 고착성을 가져야 가장 올바른 HA의 그림이 나옴
# pcs resource defaults update resource-stickiness=1000
Warning: Defaults do not apply to resources which override them with their own defined values
("pcs resource defaults" 명령은 "pcs resource defaults update"로 대체됩니다.)# pcs resource defaults
Meta Attrs: rsc_defaults-meta_attributes
resource-stickiness=1000
☞ VIP 리소스 생성 및 본딩 인터페이스에 할당
bond0라는 인터페이스에 붙어서 동작되고 감시주기는 30초 빈도로 설정
주의할 점은 양 쪽 노드의 같은 인터페이스 명 즉, bond0가 존재해야 됨
# pcs resource create VIP IPaddr2 ip=111.222.333.248 cidr_netmask=24 nic=bond0 op monitor interval=30 --group lilo-db# pcs resource
* Resource Group: lilo-db:
* VIP (ocf::heartbeat:IPaddr2): Started lilo-hb1# ip a |grep bond0
5: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
inet 111.222.333.241/24 brd 111.222.333.255 scope global noprefixroute bond0
inet 111.222.333.248/24 brd 111.222.333.255 scope global secondary bond0
☞ 생성된 VIP Health Check 리소스 생성
Pacemaker에서 Network Monitoring은 ethmonitor, ping 2개로 나뉨
ethmonitor는 실제로 잡혀있는 인터페이스 상태를 기준으로 Health Check를 함
ping 방식은 ping을 host_list로 주기적으로 보내서 체크
# pcs resource create VIP-monitor ethmonitor interface=bond0 clone# pcs resource
* Resource Group: lilo-db:
* VIP (ocf::heartbeat:IPaddr2): Started lilo-hb1
* Clone Set: VIP-monitor-clone [VIP-monitor]:
* Started: [ lilo-hb1 lilo-hb2 ]
☞ 생성된 VIP의 제약조건 설정
서비스의 다운타임 최소화를 위해 Auto Failback을 방지 시킴
# pcs constraint location vip rule score=-INFINITY ethmonitor-bond0 ne 1
- Pacemaker 클러스터 설치(RHEL/CentOS 8 version별 차이)
- HA의 필요성
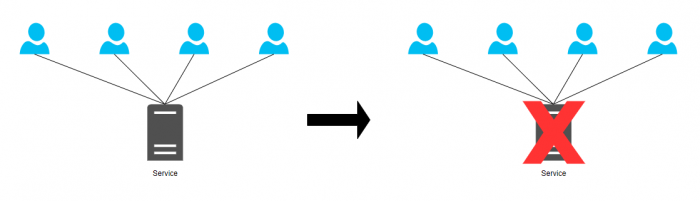
서버 한대로 서비스를 구성 했을 시 서비스에 문제가 생기면 서버 한대에서만 서비스가 돌아가고 있었기 때문에 장애시간동안 서비스가 원활이 되지 않아 금전적으로나 손해가 발생한다.

이중화 시 Service의 문제가 생겼을 시 자연스레 Standby 서버로 넘어가기 때문에 장애의 발생이 급격히 줄어든다.
※ HA의 필요성
http://www.chlux.co.kr/bbs/board.php?bo_table=board02&wr_id=43&sca=OS&page=3
- 소개
중요한 서비스를 무중단으로 운영하기 위한 클러스터 구축 (Only Active - Stand By)
- 클러스터 주요 구성 요소
# Cluster Information Base (CIB) : 클러스터 정보 자료로 모든 클러스터의 옵션, 노드, 자원, 서로 간의 관계 및 현재 상태에 대한 정의 설정 업데이트에 대해 모든 노드 동기화
# Cluster Resource Management Daemon (CRMd) : 클러스터 리소스 관리 데몬으로 노드 중 하나를 마스터로 선택하여 모든 클러스터 의사 결정을 중앙 집중화
(Virtual IP 리소스 할당을 위해 내부적으로 corosync 사용)
# 쿼럼디스크 : 디스크 기반 쿼럼 데몬.
- 구성
(Active - Stand by)

- 환경
Hardware
- VMware ESXI
OS
- CentOS 8.1-1911 x2
- RHEL 8.1 x2
Service
- Mysql 8.0
- Setup
0. 공통 사항
1. HA Package 설치를 위한 repo 구성
2. HA Cluster Install&Configuration
3. Service(Application) 확인
4. Constraint 설정
5. Failover 기본 순서
- 사전 준비 사항
물리서버 기준)
Service Network(이중화), Heartbeat Network(이중화) Split brain 대비
Fence Device 구성을 위한 ILO, IDRAC, RSA IPMI Appliance 계정 및 static IP 필요
서비스 Resource 등록을 위해 Shared Volume(Storage) 필요
※ Split brain
http://www.chlux.co.kr/bbs/board.php?bo_table=board02&wr_id=88&sca=OS
가상화서버 기준)
VM기준 이중화는 되지만 버그가 있어 ICMP 확인이 불가.
이중화는 안하는것으로 권고
Service Network, Heartbeat Network,
Fence Device 구성을 위해 VMware의 경우 Vmware 접속 Admin 계정, Password, IP 필요
서비스 Resource 등록을 위해 Shared Volume(Storage) 필요
- Setup (2 Node 구성)
0. 공통 사항
0.1. 방화벽&SElinux disable로 변경

0.2. /etc/hosts파일 설정
1. HA Package 설치를 위한 repo 구성
(CentOS 8 기준)
1.1. DNS 구성
1) resolv.conf 복사

- 기존 7버전까지만 해도 /etc/resolv.conf가 있었지만 8버전 이후로 /etc/resolv.conf파일이 존재하지 않는다.
2) resolv.conf 설정

- 외부와 통신할 수 있게 nameserver ip수정이 꼭 필요
1.2. HA repo 구성
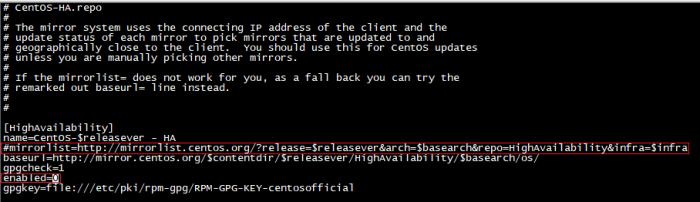
- CentOS HA Package는 외부에서 받아오기때문에 외부망과 연결이 필요
변경점)
# mirrorlist 주석 해제
enabled=0 -> enabled=1
1.3. repolist 확인

(RHEL 8 기준)
1.4. DNS 구성
- RHEL 8 HA package는 iso 마운트 후 package를 설치하기 때문에 외부와의 연결은 불필요
1.5. HA repo 구성

- RHEL 8버전 부터는 HA Package를 iso파일에 없기때문에 따로 iso 파일을 받아야 합니다.
- BaseOS, AppStream은 기존 dvd package로 구성
1.6. repolist 확인

2. HA Cluster Install&Configuration
- Package 설치 (양 node 설치 진행)

- 클러스터 구성을 하기 위한 필요 패키지들을 설치 진행
- pcs와 fence-agents-all 설치 시 dependency 패키지로 pacemaker, corosync 패키지가 같이 설치 된다.
2.1. cluster 계정 패스워드 등록 (양 node 같이 등록)

- HA Cluster 인증을 위해 hacluster 계정의 패스워드를 등록
- hacluster 계정은 패키지들이 설치 되면서 자동적으로 생성
- 계정의 비밀번호가 다르면 인증이 되지 않으니 같은 비밀번호로 등록 요망
2.2. pcs daemon 시작 (양 node 시작)

- pcsd : pacemaker/corosync 설정, 관리 daemon
2.3. 각 노드 인증
1) RHEL/CentOS 7

2) RHEL/CentOS 8

- 클러스터에 들어갈 노드를 서로 인증하는 절차
- 7버전과 8버전의 노드 인증 명령어(cluster -> host)가 변경
2.4. 클러스터 구성
1) RHEL/CentOS 7
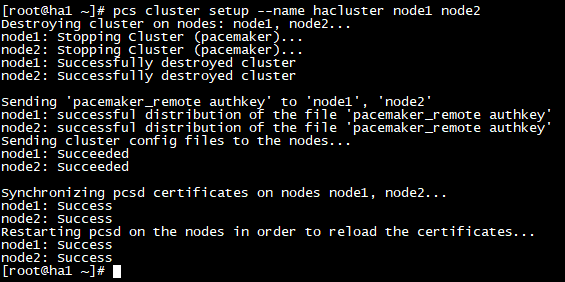
2) RHEL/CentOS 8
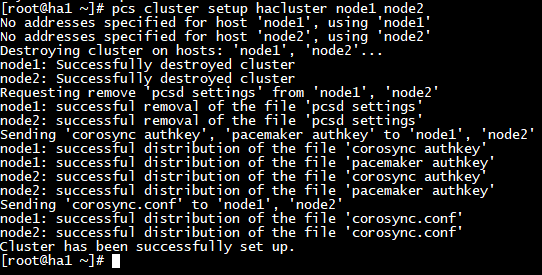
- 클러스터에 몇개의 노드가 들어가는지, 노드들의 이름을 적고 클러스터의 이름을 설정
변경점)
- RHEL/CentOS 7 : pcs cluster setup --name hacluster node1 node2
- RHEL/CentOS 8 : pcs cluster setup hacluster node1 node2
- 8버전 부터는 --name옵션이 빠지고 바로 클러스터 이름을 명시
2.5. 클러스터 시작

2.6 클러스터 상태 확인
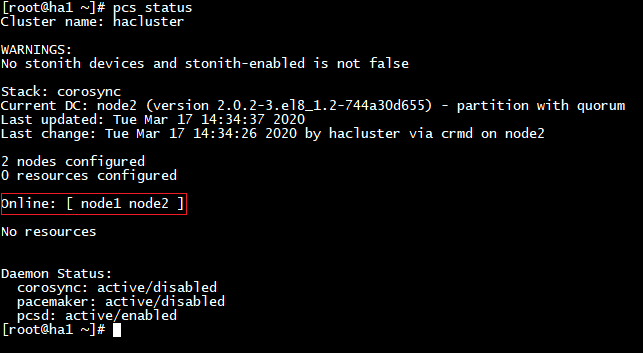
- Online: [ node1 node2] : online상태로 확인이 되었다면 클러스터에 2 node가 등록
2.7. cluster 기본 셋팅
- 장애 처리 후 리소스 이동 방지 설정
# pcs property set default-resource-stickiness=100
- 리소스 등록 시 fence device 작동 방지
# pcs property set stonith-enabled=false
- 리소스 등록이 끝나게 되면 fence device 작동 할 수 있도록 변경
# pcs property set stonith-enabled=true
- 2 node 구성 할 시 일반적으로 quorum 설정을 disable
# pcs property set no-quorum-policy=ignore
- 셋팅 확인
# pcs property show
3. Service(Application) 확인
- HA Cluster에 등록 될 수 있는 Service(Application) 확인
ex) Oracle DB, Mysql, 기타 등등..
4. Constraint 설정
- 리소스의 위치나 순서, 동거 조건을 제약하는 설정
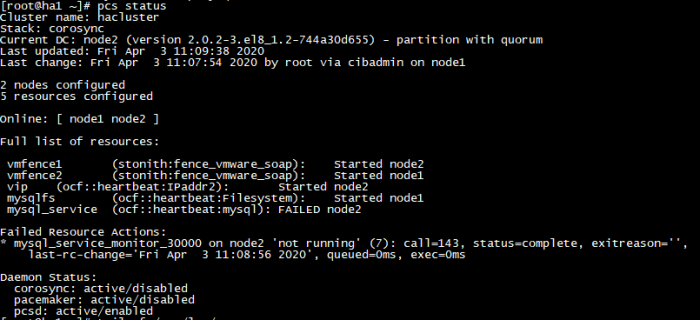
- 리소스 등록 후 기본 위치는 위의 사진과 같이 중구난방으로 위치하게 된다.
- 리소스 조건을 정의하지 않으면 failover시 어떠한 에러가 발생할 지 모른다.
- 그러므로 리소스들을 한데 뭉쳐 그룹화 하거나 constraint 설정을 하여야 한다.
4.1. 리소스 위치 제약 조건
- 기본 포맷
# pcs constraint location <resource-name> prefers <node[=score]>
- 어떤 리소스가 어떤 노드에서 실행 될 것인지 결정
- score의 기본 값은 INFINITY
# pcs constraint location <resource-name> avoids <node[=score]>
- 어떤 리소스가 어떤 노드에서 실행 되지 말아야 하는지 결정
- score는 마찬가지로 기본 값은 INFINITY
4.2. 리소스 순서 제약 조건
- 기본 포맷
# pcs constraint order start <first-resource-name> then <second-resource-name>
- 어떤 리소스가 먼저 시작되고 늦게 시작 될 것인지 결정
ex) 위 사진과 같이 리소스들이 그룹으로 되지 않았다면 order 조건으로 순서를 결정해 주어야 한다.
failover 시 node2에서 vip up, filesystem up, mysql_service up 순으로 결정한다면
# pcs constraint order start vip then mysqlfs
# pcs constraint order start mysqlfs then mysql_service
- 이와 같이 순서를 정의
- 이미 그룹으로 리소스들을 한데 묶었다면 진행을 하지 않아도 무방
4.3. 리소스 동거 제약 조건
- 기본 포맷
# pcs constraint colocation add <resource-name> with <resource-name> [score]
- 어떤 리소스와 함께 있어야 하는지 결정
5. Failover 기본 순서
node1) Service down -> Filesystem umount(Shared Volume) -> VIP down
ndoe2) VIP up -> Filesystem(Shared Volume) mount -> Service up
HA 구성 후 운영 메뉴얼
- http://www.chlux.co.kr/bbs/board.php?bo_table=board02&wr_id=90&sca=OS
[시스템 환경]
VirtualBox
CentOS 7
192.168.56.102 node01
192.168.56.103 node02
Pacemaker
Corosync
가상환경 설정
: [호스트-게스트], [게스트-게스트] 통신 을 위한 설정
VirtualBox 네트워크 설정
[어댑터 1] NAT 설정 및 포트 포워딩
포트 포워딩 설정
node 1 - ssh port 9001
node 2 - ssh port 9002
[어댑터 2] 호스트 전용 어댑터
● 각 서버 hosts 설정
: 각 서버 노드 ip 를 확인하여 설정해 준다.
vi /etc/hosts 아래 내용 추가
192.168.56.102 node01
192.168.56.103 node02
Pacemaker / Corosync 설치
● pacemaker 설치 :::: 모든 호스트
# yum install -y pcs fence-agents-all
● pcs 데몬 시작 및 서비스 활성화
# systemctl start pcsd.service
● 패스워드 적용
: 패키지 설치 후, 시스템에 hacluster 사용자가 자동으로 생성됩니다. 관리의 편의성을 위해 hacluster 사용자에 대한 동일한 패스워드를 적용합니다.
# passwd hacluster
● Pacemaker 설정
: 호스트간 통신을 위해 Firewall에서 클러스터 트래픽을 허용.
TCP : Ports 2224, 3121, 21064
UDP: Ports 5405
# firewall-cmd --permanent --add-service=high-availability
# firewall-cmd --add-service=high-availability
# firewall-cmd --reload
● 두 노드의 통신을 위한 설정
# pcs cluster auth node01 node02
[패스워드 입력]
Username: hacluster
[입력 후 화면]
node01: Authorized
node02: Authorized
● Corosync 구성 동기화
: --name 옵션은 원하는데로 지정. corosync 설정 파일이 생성되고 모든 노드에 배포된다.
설정 파일 위치: /etc/corosync/corosync.conf
# pcs cluster setup --name hacluster node01 node02
[명령 실행 후 화면]
Shutting down pacemaker/corosync services...
Redirecting to /bin/systemctl stop pacemaker.service
Redirecting to /bin/systemctl stop corosync.service
Killing any remaining services...
Removing all cluster configuration files...
node01: Succeeded
node02: Succeeded
[참고] To initialize the corosync config file, execute the following pcs command on both nodes, filling in the information in <> with your nodes' information. # pcs cluster setup --force --local --name mycluster
● 클러스트 시작하기
: node01에서 다음의 명령을 실행.
# pcs cluster start --all
● 부팅 시 pacemaker와 corosync 시작을 위해 두 호스트의 서비스를 활성화.
# systemctl enable corosync.service
# systemctl enable pacemaker.service
● 클러스터 상태 확인
# pcs status
[결과]
2 nodes configured
0 resources configured
Online: [ node01 node02 ]
No resources
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: inactive/disabled
● STONITH 비활성 및 Quorum 무시
# pcs property set stonith-enabled=false
# pcs property set no-quorum-policy=ignore
● 가상 IP 주소 설정
# pcs resource create Cluster_VIP ocf:heartbeat:IPaddr2 ip=192.168.56.104 cidr_netmask=24 op monitor interval=20s
[확인] pcs status
Cluster_VIP (ocf:heartbeat:IPaddr2): Started node01
python 테스트 코드 작성
● python 테스트 코드 작성
# mkdir /usr/local/cafe24
# vi /usr/local/cafe24/python_demo_service.py
if __name__ == '__main__':
import time
while True:
print('Hello from the Python Demo Service')
time.sleep(5)
실행 테스트,
# python /usr/local/cafe24/python_demo_service.py
권한 설정,
# chmod 755 /usr/local/cafe24/python_demo_service.py
● 서비스 등록
vi /etc/systemd/system/python_demo_service.service
# systemd unit file for the Python Demo Service
[Unit]
# Human readable name of the unit
Description=Python Demo Service
[Service]
# Command to execute when the service is started
ExecStart=/usr/bin/python /usr/local/cafe24/python_demo_service.py
- 서비스 실행 및 확인
systemctl start python_demo_service
systemctl status python_demo_service
[실행중 상태 확인]
● python_demo_service.service - Cluster Controlled python_demo_service
Loaded: loaded (/etc/systemd/system/python_demo_service.service; static; vendor preset: disabled)
Drop-In: /run/systemd/system/python_demo_service.service.d
└─50-pacemaker.conf
Active: active (running) since 금 2019-09-06 14:04:36 KST; 42min ago
Main PID: 1560 (python)
CGroup: /system.slice/python_demo_service.service
└─1560 /usr/bin/python /usr/local/cafe24/python_demo_service.py
- 부팅시 서비스 실행되도록 설정,
systemctl enable python_demo_service
● 사용할 수 있는 모든 리소스 리스트 출력
: systemd에 등록하면, 해당 서비스를 리소스로서 사용할 수 있게 된다.
(아래 명령어 결과 리스트에 서비스명이 나옴)
# pcs resource list
● 리소스 등록
# pcs resource create python_demo_service systemd:python_demo_service
● 리소스 등록 확인
# pcs status
● Colocation 제약 구성
: 리소스 Cluster_VIP 와 python_demo_service 는 묶음으로 같은 node에서 이루어 지도록 제약을 설정.
# pcs constraint colocation add Cluster_VIP python_demo_service INFINITY
[참고] 개별 리소스 수동으로 시작 및 중지 방법
# pcs resource enable [resource_id]
# pcs resource disable [resource_id]
ex. # pcs resource disable python_demo_service
테스트
- 설정된 가상 IP 설정이 제대로 이루어 지는지 확인.(VIP=192.168.56.104)
- node01 실행 중, secureCRT로 192.168.56.104:22로 접속시 node01로 접속됨. node01 시스템 종료 후 node02 실행 중일때 192.168.56.104:22로 다시 접속시 node02 시스템으로 접속됨.
- 서버 장애에 대한 가상 IP와 리소스 전환이 잘 이루어지 지는지 확인.
- 2-1. node01에서 실행중인 상태에서, node01에 대한 시스템 종료시 node02로 전환을 pcs status를 통해 확인함.
- 장애에 대한 데몬 리소스의 노드 전환이 잘 이루어 지는지 확인.
- Colocation 제약 조건 확인.
- 4.1. 리소스 Cluster_VIP 와 python_demo_service 가 node02인 곳에서 실행되고 있을때, python_demo_service 리소스만 stop 시켰을 경우, 조금 시간이 지난뒤 다시 start 됨. node01과 node02 끼리 주고받는 heartbeat interval 에 따라 다시 실행되는 시간이 달라지는 것을 추정됨.
- node01 실행중, node01를 재부팅 했을때 다시 node01에서 실행됨.
유의사항
- 문제가 발생하여 노드 전환이 발생했을 때 작업에 영향이 있을지 확인이 필요
참고 사이트
● 공식 문서
: 세부 옵션은 공식 문서 참고를 추천
● 가상환경 설정 참고 블로그 https://dbrang.tistory.com/1279
● 기본 설치 가이드 참고 블로그 https://m.blog.naver.com/PostView.nhn?blogId=bokmail83&logNo=220569260474&proxyReferer=https%3A%2F%2Fwww.google.com%2F
[리눅스/Linux] Pacemaker 이중화 설치 방법(Active-Standby 구성)
OS Version
- CentOS 7.7.1908
클러스터 세팅 방법
1. Pacemaker 패키지 설치(Active/Standby)
# yum install -y pacemaker corosync pcs psmisc policycoreutils-python
2. hosts 파일 수정
# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 SVR-01 ::1
localhost localhost.localdomain localhost6 localhost6.localdomain6
#Active
192.168.1.101 node1
#Standby
192.168.1.102 node2
3. Pacemaker 서비스 시작 및 등록(Active/Standby)
systemctl start pcsd.service
systemctl enable pcsd.service
4. 클러스터 계정 설정
# passwd hacluster
[root@SVR-01 ~]# passwd hacluster
Changing password for user hacluster.
New password:
Retype new password:
passwd: all authentication tokens updated successfully
5. hacluster 계정을 각 노드에 인증(Active/Standby)
- 4번 항목에서 입력했던 패스워드를 입력
# pcs cluster auth [hostname1] [hostname2]
[root@SVR-01 ~]# pcs cluster auth node1 node2
Username: hacluster
Password:
node1: Authorized
node2: Authorized
- Error: Uable to communicate with node2와 같은 에러 발생 시 클러스터에서 사용하는 포트 오픈(방화벽 등)을 확인해야 합니다.
- 클러스터 활성화 필요 포트 리스트
| 포트 | 용도 |
| TCP 2224 | 모든 노트에 필요(pcsd 웹 UI와 노드 간 통신에 필요) |
| TCP 3121 | 클러스터에 Pacemaker 원격 노드가 있는 경우 모든 노드에 필요 |
| TCP 5403 | |
| UDP 5404 | corosync 멀티 캐스트 UDP에 대해 구성된 경우 corosync 노드에 필요 |
| UDP 5405 | 모든 corosync 노드에 필요 |
| TCP 21064 | 클러스터에 DLM이 필요한 리소스가 포함된 경우 모든 노드에 필요 |
| TCP 9929 UDP 9929 |
부스 티켓 관리자를 사용하여 다중 사이트 클러스터를 설정하는 경우 모든 클러스터 노드 및 부스 중재자 노드에서 동일한 노드의 연결에 대해 열어 있어야 함 |
6. 클러스터 생성(Active/Standby)
# psc cluster setup --name [cluster name] node1 node2
[root@SVR-01 ~]# pcs cluster setup --name sqisoft node1 node2
Destroying cluster on nodes: node1, node2...
node2: Stopping Cluster (pacemaker)...
node1: Stopping Cluster (pacemaker)...
node2: Successfully destroyed cluster
node1: Successfully destroyed cluster
Sending 'pacemaker_remote authkey' to 'node1', 'node2'
node1: successful distribution of the file 'pacemaker_remote authkey'
node2: successful distribution of the file 'pacemaker_remote authkey'
Sending cluster config files to the nodes...
node1: Succeeded
node2: Succeeded
Synchronizing pcsd certificates on nodes node1, node2...
node1: Success
node2: Success
Restarting pcsd on the nodes in order to reload the certificates...
node1: Success
node2: Success
7. 클러스터 기동(Active)
# pcs cluster start --all
[root@SVR-01 ~]# pcs cluster start --all
node1: Starting Cluster (corosync)...
node2: Starting Cluster (corosync)...
node1: Starting Cluster (pacemaker)...
node2: Starting Cluster (pacemaker)...
8. 클러스터 status 확인(Active/Standby)
# pcs status
9. STONITH 비활성 및 Quorum 무시설정(Active)
- STONITH 설정은 데이터의 무결성을 확보하기 위해 기본적으로 활성화되어 있는 상태로 비활성화가 필요하다.
# pcs property set stonith-enabled=false
# pcs property set no-quorum-policy=ignore
가상 IP(vip) 세팅하기
1. vip 세팅(Active)
# pcs resource create Cluster_VIP ocf:heartbeat:IPaddr2 ip=192.168.1.100 cidr_netmask=24 op monitor interval=20s
2. vip 확인(Active/Standby)
- ip addr 명령어 입력 시 지정한 vip 확인되면 된다.
# pcs status
# ip addr
Fail-over 테스트
1. Active 서버 클러스터 중지 후 vip Standby 서버로 전환 확인
# psc cluster stop node1
2. 가중치 설정하기
- Pacemaker 이중화는 가중치를 변경해서 vip를 이동시킬 수 있다.
- 양 서버 간 가중치가 같다면 fail-over 상황에서 vip가 이동하지 않는다.
- 가중치를 변경할 시 가중치가 더 높은쪽으로 vip가 이동한다.
- 가중치 설정 명령어
# pcs constraint location Cluster_VIP prefers node1=100
# pcs constraint location Cluster_VIP prefers node2=50
- 가중치 확인 명령어
# pcs constraint show
'ㆍ Linux' 카테고리의 다른 글
| rtkit, RealtimeKit, rtkit-daemon, 실시간 정책 및 Watchdog 데몬 (0) | 2023.07.20 |
|---|---|
| sar, sysstat, 리눅스 지표 분석 도구, nice, renice, 리눅스 서버 60초안에 상황 파악 (0) | 2023.07.17 |
| 리눅스 시스템 모니터링 시스템 최적화 (0) | 2023.06.23 |
| sar 명령어를 이용한 시스템 모니터링, LINUX (0) | 2023.06.20 |
| 서버 상태 파악, 리눅스, Linux (0) | 2023.06.09 |