
리눅스 모니터링 및 로그 상태 점검
> Linux 리눅스 실시간 로그 : tail -f /var/log/messages
> 현재 설정된 연결 : watch -n1 -d "netstat -an | grep ESTABLISHED | wc -l"
> 포트 80에 연결된 IP가 있는지 확인하기 위해 현재 활성 연결을 확인 : netstat -n|grep :80|cut -c 45-|cut -f 1 -d ':'|sort|uniq -c|sort -nr|more
> 접속 IP 그래프 : netstat -an|grep ESTABLISHED|awk '{print $5}'|awk -F: '{print $1}'|sort|uniq -c|awk '{ printf("%s\t%s\t",$2,$1); for (i = 0; i < $1; i++) {printf("*")}; print ""}'
> 로그환경파일 : /etc/syslog.conf (sysctl.conf, syslogd.conf)
> 보안 로그 실시간 모니터링 ( inetd 또는 xinetd 로그 기록 모니터링) : tail -f /var/log/secure
> 시스템로그 실시간 모니터링 : tail -f /var/log/messages
> 메일관련 로그 실시간 모니터링 : tail -f /var/log/maillog
> cron 로그모니터링 : tail -f /var/log/cron
> sar : System Activity Report
sar -u
sar -q
sar -r
sar -n
sar -W
> 부팅시의 메시지 확인 : tail -f /var/log/boot.log
> 부팅시의 로그기록 검색 : dmesg | grep 관련문자
> 부팅 로그 확인 : /var/log/messages
last reboot | less
last -x | less
last -x | grep shutdown | less
last -x shutdown
last -x shutdown reboot
last -x | head | tac> 서버 모델 정보 : dmidecode -s system-product-name
> OS 버전 확인 : cat /etc/*-release | uniq
> 오라클 리눅스 버전 확인 : rpm -qa *-release
> OS 배포 버전 확인 (커널 및 release) :
uname -a (uname -r , hostnamectl | grep Kernel , cat /proc/version , last reboot | head -1 , last | grep reboot | head -1 , rpm -qa kernel , yum info installed kernel | egrep "^Version|^Release" , yum list installed | grep ^kernel )
> 메모리 사용량 간단히 보기 : ps -ef --sort -rss
> 메모리 상위 10 : ps -ef --sort -rss | head -n 11
> 메모리 사용량 top10 : ps -eo user,pid,ppid,rss,size,vsize,pmem,pcpu,time,cmd --sort -rss | head -n 10
> CPU 개수 확인 : lscpu|egrep '^Thread|^Core|^Socket|^CPU\('
> CPU 정보 확인 : cat /proc/cpuinfo
> CPU 모델 정보 확인 : cat /proc/cpuinfo | grep 'model' | tail -1
> 물리적 CPU 갯수 : grep 'physical id' /proc/cpuinfo | sort | uniq | wc -l
> CPU 코어 전체 개수 확인 : grep -c processor /proc/cpuinfo
> 물리 CPU 수 확인 : grep "physical id" /proc/cpuinfo | sort -u | wc -l
> CPU당 물리 코어 수 확인 : grep "cpu cores" /proc/cpuinfo | tail -1
> 논리적 CPU 수량 : grep ^processor /proc/cpuinfo | wc -l
> 코어 수량 : grep 'cpu cores' /proc/cpuinfo
> 하드디스크 물리적 수량, 용량 : fdisk -l | grep Disk
> 하드디스크 물리적 수량, 용량 상세 : fdisk -ul
> 물리 메모리 개수 및 용량 : dmidecode | grep 'Size.*MB'
> 메모리 정보 확인 : cat /proc/meminfo
> 하드디스크 정보 확인 : dmesg | grep sda
> SCSI 타입의 하드디스크 정보 확인 : dmesg | grep SCSI
> IDE 타입의 하드디스크 정보 확인 : dmesg | grep had
> NIC 정보 확인 : dmesg | grep eth
> USB 장치에 관한 정보 : dmesg | grep usb
> 커널 정보 확인 : dmesg | grep Linux
> 메모리 정보 확인 : dmesg | grep memory
> 사용 포트 확인 : netstat -tnlp
> 사용 IP : netstat -rn
> 활성중인 서비스 포트 확인 : netstat -atun
> 서비스 포트 확인 : netstat -ano
> IP정보 테이블 확인 : /etc/sysconfig/network-scripts/ifcfg-eth0
service network restart
Linux 6.x
> 방화벽 설정 위치 : /etc/sysconfig/iptables 혹은 iptables-config
> 방화벽 설정 확인 : iptables -L
> 방화벽 가동 시작 : /etc/init.d/iptables start
> 방화벽 설정 확인 : /etc/init.d/iptables status
> 방화벽 서비스 정지 : service iptables stop
> 방화벽 중지 : chkconfig iptables off
Linux 7.x
> 방화벽 설정 확인 및 해제 : 부팅시 해제 (vm 생성시 디폴트로 방화벽 데몬 설정됨 -> 불필요시 disable)
systemctl status firewalld, systemctl stop firewalld, systemctl disable firewalld
Linux 8.x
> 방화벽 시작, 부팅시 자동 시작 : systemctl start firewalld, systemctl enable firewalld
> 방화벽 중지 : systemctl disable firewalld
> 방화벽 재시작 : firewall-cmd --reload
> 방화벽 설정 확인 : firewall-cmd --state (--check-config, --runtime-to-permanent)
> 현재 zones의 설정 상태 확인 : firewall-cmd --get-zones
> public zones의 설정 상태 확인 : firewall-cmd --zone=public --list-all
> 현재 로그인한 사용자 상태 정보를 담고 있는 로그 삭제 : cat /dev/null > utmp
> 실패한 로그인 정보를 담고 있는 로그 삭제 : cat /dev/null > btmp
> 성공한 로그인/로그아웃 정보, 시스템 부트/셧다운 로그 삭제 : cat /dev/null > wtmp
> 마지막으로 성공한 로그인 정보를 담고 있는 로그 삭제 : cat /dev/null > lastlog
> 명령어 히스토리 로그 삭제 : history -c
> 해당 디렉토리에 있는 디렉토리 및 파일 용량 확인 : du -sh *
> 폴더가 여러개 있을때 크기 순 부터 확인 하고 싶을 때 : du -sh * | sort -hr
> 숨겨진 파일(ls -al) 포함해서 용량 확인 : du -h --max-depth=1
> 특정 날짜 기준으로 파일 확인 : ll --time-style full-iso | awk '{print $6" "$9}' | grep 2011-08
> 특정 날짜 기준으로 파일 삭제 : ll --time-style full-iso | awk '{print $6" "$9}' | grep 2011-08 | awk '{print $2}' | xargs rm -f
> 서버의 언어 설정 확인 : echo $LANG
> boot level에 따른 데몬 설정 보기 : chkconfig --list
> 현재 세션 언어 바꾸기 : LANG=en_US.UTF-8
> 언어 설정 영구적으로 변경 :
vi /etc/sysconfig/i18n (혹은 vi /etc/locale.conf)
LANG="ko_KR.UTF-8"
LANG="en_US.UTF-8"
SYSFONT="latarcyrheb-sun16"
source /etc/sysconfig/i18n (혹은 /etc/locale.conf)
localectl set-locale LANG="ko_KR.UTF-8"
echo $LANG
> CentOS 7 이후 : export LANG="ko_KR.UTF-8"
> 서버의 언어 설정 확인 : localedef -c -i ko_KR -f UTF-8 ko_KR.UTF-8
> 현재 세션 언어 바꾸기 : localectl set-locale LANG=ko_KR.UTF-8
> 언어 설정 영구적으로 변경 : 재부팅 또는 로그아웃/재로그인
> NTP 설정 : vi /etc/ntp.conf
server NTP아이피 prefer
service ntpd restart
ntpq -p
> DNS Zone 파일 위치 : /var/named
> DNS 서비스 종료 : systemctl stop named
> DNS 서비스 시작 : systemctl start named
> hostname 위치 : /etc/hostname
> 호스트명 영구적 변경 : hostnamectl set-hostname 호스트명
> root 로긴 접속 제한 : vi /etc/ssh/sshd_config -> PermitRootLogin를 yes 혹은 no
service sshd restart (리눅스 6)
systemctl restart sshd (리눅스 7)
> 모든 서비스 동시 접속자 수 : netstat -nap | grep ESTABLISHED | wc -l
> 웹 동시 접속자 수 : netstat -nap | grep :80 | grep ESTABLISHED | wc -l
> 웹서버 커넥션수 체크 : netstat -n | grep -F :80|egrep '(ESTAB|SYN)'|awk '{print $5}'|sed 's/:[0-9]*//'|sort -u|wc -l
> nmap으로 열려있는 포트만 확인 : nmap -sT -O localhost
> 윈도우 uptime 확인 : C:\> wmic os get lastbootuptime
C:\> net stats server
빠르게 Log 확인하기
가장 종합적인 Log를 보려면 "/var/log/message"를 확인하는 것이 좋습니다. 그런데 Message에 쌓인 양이 너무 방대해서 감당이 안된다 싶으면 일단 1차적으로 에러 구문만 찾아보고 빠르게 스캔하는 방법도 있습니다.
이 방법은 서버 대상이 너무 많을 떄 쓰는 임시적인 방법으로 장애가 발생한 서버를 분석할 때 해당 명령어를 사용해서 분석하는 것은 권하지 않습니다. 장애가 난 서버는 앞 글에 썼던 전체적인 서버 성능 지표 확인과 Log를 자세히 볼 필요가 있습니다.
일단 아래의 명령을 쳐서 결과 값을 먼저 확인합니다.
# cat /var/log/messages-20210502 |egrep -i "critical|error|warn|alert|fault|fail"

위의 명령을 쳐서 에러가 난 부분을 빠르게 찾고 서버에 크리티컬 한 영향을 줄만한 것들을 다 잡아냅니다. "grep"을 잡은 조건은 dmesg의 경고 수준에 따라 위험 요소가 있는 것입니다.
- Critical: 서버에 크리티컬한 영향
- err: 에러(오류) 조건
- warn: 경고 조건
- alert: 즉시 조치가 필요함
- notice: 정상이지만 주기적으로 확인이 필요한 상태
- info: 인포성으로 시스템에 영향이 없음
서버 상태 파악하기
처음 보는 서버나 많이 접하지 않아서 낯설은 서버들을 접하는 경우가 일을 하다 보면 많이들 생길 것입니다. 아래의 명령으로 모든 것을 알 수는 없지만 대략적으로 서버가 어떤 자원을 많이 사용하고 있고 어떤 솔루션이 사용되고 있는 서버인지를 알아가는 단계라고 생각하시면 좋을 것 같습니다.
처음 가서 서버 상태를 대략적으로 본 후 만약 모니터링 툴을 따로 가지고 있다면 추가적으로 보는 것이 좋습니다.보통 Jennifer Soft의 Jennifer, Prometheus+Grafana, Zabbix 등의 모니터링 툴을 많이 사용합니다. (APM: Jennifer Soft의 Jennifer, Opennaru의 KHAN 등)
간단한 서버 성능 지표를 보기 위해 아래의 패키지를 설치해줍니다.
# yum install sysstat

해당 패키지에는 sar, vmstat, iostat 등 현재 리소스 상태 혹은 타임 스태프별로 성능 지표를 보기 적합한 명령어들이 있습니다. 설치가 완료됐으면 본격적으로 서버 상태를 확인하기 시작합니다.
먼저, 서버가 언제 마지막으로 재기동된 날짜 및 Load Average 지표를 확인하는 명령어를 입력합니다.
# uptime
# grep -c processor /proc/cpuinfo


이 서버는 1일 전에 22시 57분에 재기동을 했고 현재 1명의 유저가 접속중인 것으로 확인됩니다. Load Average는 0.0X대로 상당히 준수한 지표를 보이고 있습니다.
가장 앞에 "22:27:57"은 "date" 명령어, Uptime 시간은 "/proc/uptime"에 초 단위로 표기 된 것을 사람이 보기 쉬운 시간으로 변경하여 우리에게 제공됩니다. Load Average 역시 "/proc/loadavg"의 수치를 가져와서 우리에게 제공합니다.
Load Average 값은 부하 수치와 직접적으로 관련된 수치이기 때문에 주의깊게 봐야됩니다. 일단 해당 서버의 CPU 코어 수는 1 Core인 것으로 보이기 때문에 정상 범위 기준 값을 1로 잡습니다.
"도대체 1이 무엇일까?" 라는 생각이 들긴 합니다. CPU 마다 작업의 처리를 기다리는 프로세스가 1개씩 있으면 부하 수치가 정상적이라고 판단을 내립니다.. 하지만 여기서 WAIT Process가 2개가 되어버리면 Load Average 값은 2가 됩니다. 실질적으로 이 서버는 처리를 기다리는 프로세스가 1개 초과가 지속적으로 유지되면 위험하다는 것입니다.
잠시 Load가 높아질 수도 있는거 아닌가요? Load Average는 1분, 5분, 15분 단위로 표기되기 때문에 만약 5분과 15분의 값이 지속적으로 높게 나온다면 정말로 위험한 것입니다. 5분과 15분의 평균 Load 값이 높다면 그건 잠시 높아지는게 아니라고 판단이 가능해지기 때문입니다.
# date
# cat /proc/uptime
# cat /proc/loadavg

여기서 숙지해야 될 것은 Load Average 값과 재기동 날짜입니다. 재기동이 날짜가 최근으로 잡혀져있다면 최근에 재기동한 이력이 있는지 물어봐야됩니다. 추가로 너무 오랫동안 재기동을 하지 않아도 따로 체크를 해놓는 것이 좋습니다.
시스템 메세지를 확인해서 부팅시부터 시작해서 커널 메세지에 이상이 없는지 확인합니다.
# dmesg

이 서버는 "enp0s3"이라는 Network Interface가 끊긴 이력이 있는 것으로 보입니다. 추가로 Log를 봐야될 것으로 보입니다. 이러한 굵직한 것들이 나오기 떄문에 서버 상태를 빨리 파악하는데 많은 도움이 됩니다.
"vmstat" 명령을 이용해 현재 서버 상태를 "top" 명령어로 보는 것보다 더 자세하게 확인합니다. 이 명령어는 Virtual Memory, 페이징 활동 및 실패, CPU 활동, Process 등의 통계들이 있어 상당히 유용하게 쓰입니다
일단 들어가자마자 확인해야 될 것은 현재 서버의 상태이기 때문에 자세한 정보보다 대략적인 상태를 보고 나서 자세히 알아보는 것이 좋은 것 같습니다. 아래의 명령어에 "1"인자를 붙여 1초 간격으로 정보를 봅니다.
# vmstat 1

뭔가 깔끔하게는 되어 있는데 처음 보면 낯설은 용어들이 보일 것입니다. 아래에 정리를 하면서 파악하려고 합니다.
○ procs(=Process, 프로세스)
1) r: 실행 큐에 쌓인 실행 대기중인 프로세스의 수 (CPU Load(부하) 예측에 유용)
2) b: I/O 자원에 대해 프로세스를 할당 받지 못해 대기하고있는 프로세스 수 (Disk 및 CPU 성능 체크 필요)
(시스템 부하시 r에서 프로세스 할당을 받아 MEM이나 Disk에 쓰려고 하는데 자원 할당을 받지 못하는 상태)
○ memory (메모리 상태)
1) swpd: Swap Partiton의 사용량
2) free: Memory 용량 중 Cache+Buffer+Shared 영역을 제외한 사용 가능한 용량 (단위: KB)
3) buff: 버퍼 메모리(Buffer Memory) 사용량, 버퍼 메모리는 한 쪽에서 다른 한 쪽(End Point)로 전송하는 동안 임시적으로 보관하는 공간 (단위: KB)
4) cache: 메인 메모리와 CPU 간의 데이터 속도 향상을 위한 중간 버퍼 역할을 해주는 메모리 (CPU, MEM 등 여러 IO 장치에 존재, 병목현상 줄여줌)
○ swap (Swap 입출력 상태)
1) si: Disk에 스왑되지 않는 메모리로 swap 공간에 있는 데이터를 실제 메모리로 호출함
2) so: 메모리에서 Disk로 Swap되는 메모리로 실제 메모리의 데이터 중 일부분을 Swap 공간으로 보냄
○ io (블럭 디바이스 입출력 상태)
1) bi: Blcok Device로 보내는 블럭 수
2) bo: Block Device로부터 받은 블럭 수
3) 판단: 위의 두 값이 노으면 HDD/SSD에 읽고 쓰는 값(I/O)이 많다는 의심을 할 수 있음
○ system
1) in: 초당 인터럽트되는 양, 이더넷 패킷이나 실시간 시계도 이부분에 포함되기 떄문에 너무 높다면 네트워크 부분을 점검할 필요가 있음
※ 인터럽트: CPU가 작업을 실행 중일 때 하드웨어나 명령 등의 변수들에 예외사항이 발생하여 잠시 Micro Processor에 알려 처리하고 다시 원래의 작업을 진행하는 것을 말함
2) cs: 초당 Context Switch되는 양, CPU에서 실행되는 작업들이 자신의 우선순위보다 높은 작업(명령) 혹은 자신에게 할당된 CPU 점유 시간이 만료되면 우선순위에서 밀리는데 이 구간에서 새로운 프로세스를 적재할 때 Context Switch(문맥 교환)가 일어난다.
○ cpu
1) us: 유저 프로세스가 CPU를 사용하는 평균 시간
2) sy: 커널에서 사용되는 시스템 프로세스가 CPU를 사용하는 평균 시간
3) id: CPU가 아무 일도 하지 않고 여유 있는 유휴상태인 평균 시간
4) wa: 디스크 입출력이 있는 상태에서 CPU가 놀고 있는 평균 시간 (WAIT I/O)
5) st: 하이퍼바이저가 vCPU(가상 CPU)를 서비스하는 동안 실제 CPU를 차지한 평균 시간 (Stolen Time)
위의 내용으로 참고해서 해당 지표들을 봤을 때 매우 안정적인 지표를 보이고 있습니다. CPU 코어 수 1개에 작업 대기가 걸린 것이 없는 것을 보아 무거운 솔루션을 돌리지 않는 것으로 예측됩니다.
다음은 CPU 코어별 사용량이 어떻게 되는지 확인하는 작업입니다.
# mpstat -P ALL 1

매우 안정적인 지표를 보이고 있고 위에 "vmstat"과 비슷한 지표들이 많기 때문에 자세한 설명은 하지 않으려고 합니다. 거의 솔루션이 돌아고 있지 않고 1코어짜리 CPU를 사용하고 있음으로 예측됩니다.
만약 여러 코어일 경우에 해당 CPU가 너무 많이 사용되고 있다는 생각이 들면 "mpstat -P <CPU ID> 1"을 입력해 1초 간격으로 CPU 상태를 받아옵니다.
"pidstat" 명령을 이용해 Process 별로 CPU를 얼마나 사용중인지 확인합니다. "top" 명령과 비슷한 Output을 가져오지만 해당 세션(스크린) 전체에 표시하는 것이 아니고 Interval 주기마다 변화되는 지표를 보여줍니다. 누군가에게 보여주거나 기록하기에 좋은 편이긴 합니다.
아래의 명령어는 1초마다 Process별로 Resource를 얼마나 사용하고 있는지 확인합니다.
# pidstat 1
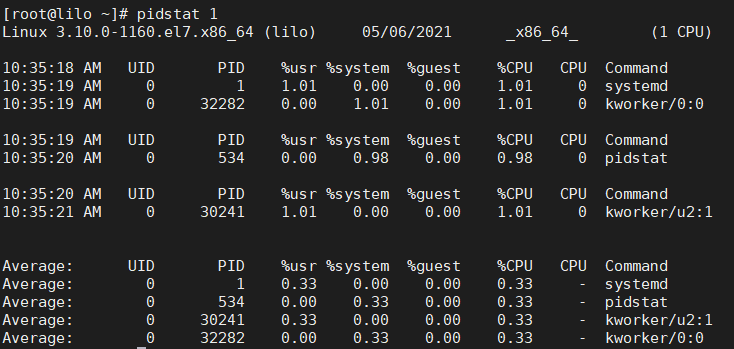
특별히 많이 잡고있는 솔루션도 보이지 않고 Load 역시 매우 안전한 편입니다.
Block Device의 성능과 관련된 지표를 확인하기 위한 "iostat" 명령을 사용합니다. 1초 간격으로 Block Device에 관한 지표를 받아 옵니다.
# iostat -xz 1

다 중요한 항목이겠지만 그 중에서 주로 보면 좋을 항목들을 아래에 정리했습니다.
- r/s: 해당 Device에 요청한 초당 읽기 요청 수
- w/s: 해당 Device에 요청한 초당 쓰기 요청 수
- rkB/s: 해당 Device에서 초당 읽어들인 데이터 블록 단위
- wkB/s: 해당 Device에서 초당 쓴 데이터 블록 단위
- await: 해당 Device에서 처리되기 위해 요청된 입출력 평균 시간(ms)
위의 지표들의 설명을 참고해 확인해본 결과 크게 문제될 이슈가 없었습니다. 앞에서 "vmstat"을 통해 메모리 부분을 자세하게 확인을 했었지만 "free" 명령어는 자주 쓰이기때문에 소개합니다. 메모리 관련된 지표들이 굉장히 깨끗하게 나오는 명령입니다.
"free" 명령어는 인자에 k, m, g를 붙여서 용량의 단위별로 확인할 수 있습니다. "g" 옵션은 아주 간단하게 볼 때는 유용하게 쓰이지만 GB 단위이기 때문에 생략된 부분이 있기 때문에 보통 "k"나 "m" 옵션을 많이 사용합니다.
# free -m

Shared, Buffer, Cache를 포함한 여유 공간인 Free 영역이 1.53G 정도 남았고 전체적으로 봤을 때도 거의 사용하지 않은 편입니다. Swap 영역도 전혀 건드리지 않았습니다.
여기서 Available 같은 경우는 Shared, Buffer, Cache 공간을 제외하고 산정된 영역으로 나중에 회수가 가능한 메모리입니다. 가끔 가다 "echo"로 특정 명령을 사용하여 캐시메모리를 줄여주는 작업을 하는 경우가 있는데 이는 OS에 행이 걸릴 수도 있는 문제이므로 사용하는 것을 자제하기 바랍니다. (특히, inode 캐시까지 없애는 3이 가장 큰 원인이 됩니다.)
그리고 만약 비우는 작업이 필요할 시 특정 솔루션으로 인해 쌓이는 경우가 많기 때문에 그 솔루션을 계속 이용한다면 어차피 다시 쌓일 확률이 높습니다. 되도록이면 캐시와 버퍼에 관한 이해도를 높인 상태에서 작업 하는 것을 권합니다.
이 Free 영역이 5%대에서 장기간 유지된다면 메모리 증설 작업이 필요할 수도 있습니다.
다음은 거의 만능에 가까운 성능 지표를 볼 수 있는 "sar" 명령어를 이용하여 네트워크 부분만 보려고 합니다. 앞에서 많은 명령으로 확인한 것이 많기 때문에 다른 지표는 생략하고 합니다. 사실 "sar" 명령의 옵션만 잘 써도 애지간한 지표들은 다 볼 수 있긴합니다.
1초 간격으로 Network Interface 별로 네트워크 처리량을 확인하기 위해 아래의 명령을 사용합니다.
# sar -n DEV 1
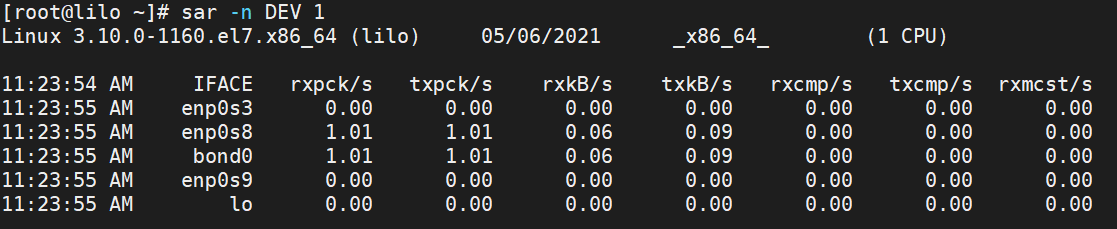

- rxpck/s: 초당 받은 패킷수
- txpck/s: 초당 전송한 패킷수
- rxkB/s: 초당 받은 bytes
- txkB/s: 초당 전송한 bytes
해당 IP로 특별한 요청도 별로 없는 것으로 보이고 이슈될 만한 문제가 없어보입니다. 왜냐면 "rxkB/s" 지표에 받은 패킷이 거의 없기 때문이고 해당 인터페이스의 경우 1Gbit/s가 최대 값이기 때문에 안정권이라고 예측하였습니다.
이제 통신량과 관련된 지표를 확인하게 아주 간단하게 네트워크와 관련된 지표를 마무리하려고 합니다. 이 작업도 "sar"를 이용합니다.
1초 간격으로 오류 및 재전송 세그먼트와 TCP 통신량을 요약해서 확인하기 위해 아래의 명령을 이용합니다.
# sar -n TCP,ETCP 1

여기서 Active와 Passive 수를 중점으로 보면 서버의 Load를 빠르게 체크할 수 있습니다. retrans/s는 네트워크 및 서버에 관한 이슈와 직결된 문제를 체크할 수 있습니다.
아래에서 3개에 대한 설명을 간단히 하려고 합니다.
- active/s: 로컬에서 요청한 초당 TCP 연결 수
- passive/s: 원격지로부터 요청된 초당 TCP 연결 수
- retrans/s: 초당 TCP 재연결 수
"top" 명령을 이용해 실시간으로 프로세스별 메모리 및 CPU 등 주요 리소스 사용량을 실시간으로 확인합니다. 이 명령은 리눅스를 사용한다면 계속 사용하게 될 명령이기 때문에 엔지니어 뿐만 아니라 리눅스를 사용한다면 개발자도 숙지해야 됩니다.
# top
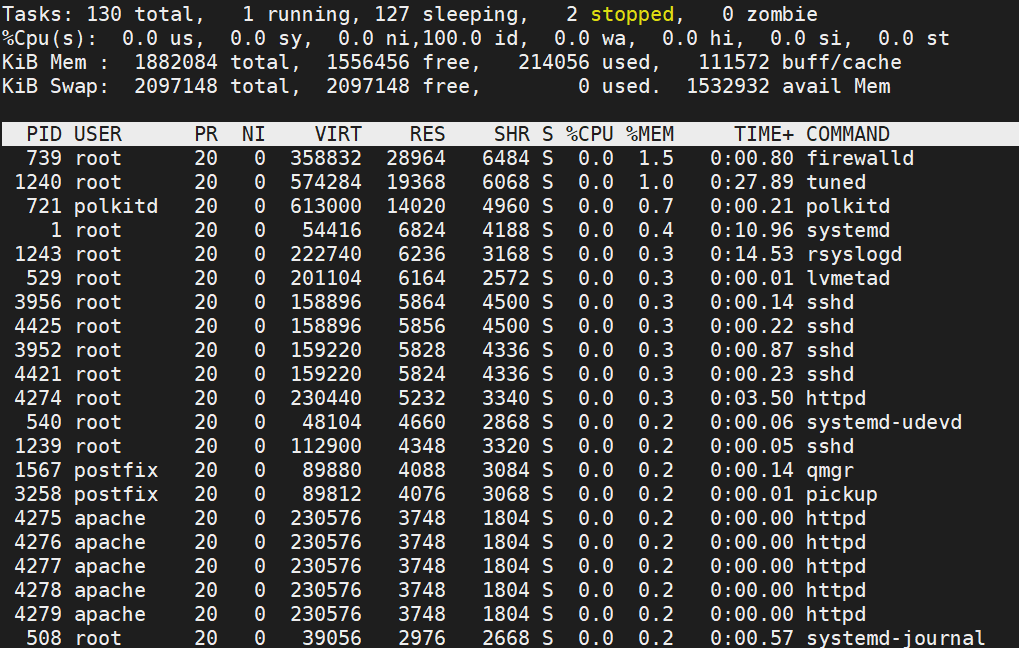
물리메모리 사용량 순

CPU 사용량 순
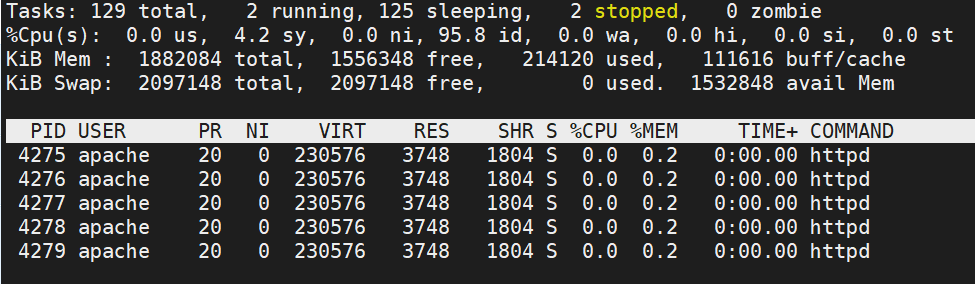
유저별 사용량
"RES"는 물리 메모리 크기이고 %CPU는 CPU 사용량입니다. 크게 이 둘만 보고있어도 빠르게 캐치 가능합니다.
- Shift + m: RES(물리 메모리) 사용량 순 정렬
- Shift + p: %CPU(CPU 사용률) 순 정렬
- Shift + U + <User Name>: 입력한 유저별 조회
○ REFERENCE
netflixtechblog.com/linux-performance-analysis-in-60-000-milliseconds-accc10403c55
Linux Performance Analysis in 60,000 Milliseconds
You log in to a Linux server with a performance issue: what do you check in the first minute?
netflixtechblog.com
'ㆍ Linux' 카테고리의 다른 글
| 리눅스 시스템 모니터링 시스템 최적화 (0) | 2023.06.23 |
|---|---|
| sar 명령어를 이용한 시스템 모니터링, LINUX (0) | 2023.06.20 |
| Ephemeral port, Well-Known Port, Registered Port, Dynamic Port, 임시 포트, 등록 포트, 시스템 포트 (0) | 2023.06.08 |
| [Linux, CentOS] 리눅스 로그 파일의 종류 및 분석 (0) | 2021.10.20 |
| [Linux, CentOS] CentOS 8, 방화벽, firewalld (0) | 2021.01.12 |