참고자료 : https://eyeballs.tistory.com/403
https://netflixtechblog.com/linux-performance-analysis-in-60-000-milliseconds-accc10403c55
Linux Performance Analysis in 60,000 Milliseconds
You log in to a Linux server with a performance issue: what do you check in the first minute?
netflixtechblog.com
b.luavis.kr/server/linux-performance-analysis
Luavis' Dev Story - 리눅스 서버 60초안에 상황파악하기
b.luavis.kr
아래 소개되는 일부 커맨드들은 sysstat package 을 설치해야 한다고 함.
아래는 ubuntu 에서 sysstat 을 설치하는 명령어
| sudo apt install sysstat -y |
1. uptime
uptime 에서 알 수 있는 정보는 다음과 같음.
- 현재시각(시:분:초 up)
- 머신 부팅 후 지속된 시간 (일, 시:분)
- 로그인한 사용자 수 (n user)
- cpu 평균 부하율 (1분/5분/15분)
여기서 말하는 cpu 평균 부하율(load average)이란, 코어 당 cpu 점유율 이라고 보면 된다.
예를 들어,
내 컴퓨터가 코어 1개만을 갖고 있고 uptime 의 평균 부하율이 1.0 이라면, cpu 는 100%만큼 일하고 있다(1.0/1*100=100%)
내 컴퓨터가 코어 1개만을 갖고 있고 uptime 의 평균 부하율이 0.7 이라면, cpu 는 70%만큼 일하고 있다(0.7/1*100=70%)
내 컴퓨터가 코어 2개를 갖고 있고 uptime 의 평균 부하율이 1.0 이라면, cpu 는 50%만큼 일하고 있다(1.0/2*100=50%)
내 컴퓨터가 코어 2개를 갖고 있고 uptime 의 평균 부하율이 2.0 이라면, cpu 는 100%만큼 일하고 있다(2.0/2*100=100%)
내 컴퓨터가 코어 4개를 갖고 있고 uptime 의 평균 부하율이 1.0 이라면, cpu 는 25%만큼 일하고 있다(1.0/4*100=50%)
내 컴퓨터가 코어 4개를 갖고 있고 uptime 의 평균 부하율이 3.0 이라면, cpu 는 75%만큼 일하고 있다(3.0/4*100=75%)
평균 점유율이 100%을 넘길때가 있다.
예를 들어 내 컴퓨터 코어는 1개인데 평균 부하율이 2.0 를 보여준다면,
cpu 는 현재 100% 만큼 일하고 있으며, 추가로 100% 만큼이 cpu 를 사용하기 위해 대기하고 있다.
시스템 운영을 위해서는 평균 부하율이 0.7 정도 나오는 것이 좋다고 함.
평균 점유율이 100%을 넘어가도 컴퓨터가 멈추거나 하는 건 아니지만,
과부하가 걸리는 것은 맞으니 시스템을 점검해야 한다고.
만약 500%가 넘어가면 그 땐 시스템에 이상이 생길 수 있으니 반드시 점검하라고 함.
uptime 은 각각 1분, 5분, 15분 동안 측정된 평균 부하율 값을 보여준다.
1분 보다는 5분, 15분의 값을 보는 것이 좋다.
uptime 이 보여주는 cpu 평균 부하율은 /proc/loadavg 의 내용을 나타낸다. 평균 부하율을 계산해서 보여주는 건 아님.
추가적으로, 내 컴퓨터의 cpu 코어 개수를 알기 위해서 아래 명령어 참고
| grep -c processor /proc/cpuinfo |
참고
webisfree.com/2020-05-30/리눅스-명령어-uptime-알아보기
klero.tistory.com/entry/리눅스-uptime-명령어와-Load-Average-분석-평균-부하율-분석
2. dmesg | tail
dmesg 는 diagnostic message 의 약어이다.
dmesg 명령어는 시스템 메세지를 확인할 수 있는 커맨드임.
부팅시에 인식한 장치 등 시스템 진단에 필요한 유용한 정보를 제공한다.
부팅 이후에도 특정 사용자의 su 전환 실패나 IO 장치 오류 등 운영에 필요한 정보를 출력한다.
부팅 이후부터 쌓인 시스템 메세지를 모두 확인 가능하기 때문에 간략하게 보기 위해 tail 을 사용하여
가장 뒤에 10개 줄만 출력한다.
시스템 메세지를 통해 성능에 문제를 줄 수 있는 에러를 찾을 수 있다고 함.
예를 들어 커널 부팅 중 생긴 에러를 이 명령어를 통해 찾아낼 수 있다.
혹은 out of memory 등의 에러가 왜 생겼는지 알 수 있다.
새로운 로그가 추가되는 것을 지켜보기 위해서 -w 옵션을 같이 사용.
마치 tail -f 명령어를 사용한 것 처럼 실시간으로 쌓이는 로그를 볼 수 있다.
| dmesg -w |
dmesg 의 로그파일 위치는 /var/log/dmesg 이다.
centos 7 이상 버전부터는 -T 옵션을 사용하여,
부팅 시작 이후 시간이 아닌 해당 로그가 찍힌 시간을 표시할 수 있다.
| dmesg -T |
참고
www.lesstif.com/lpt/log-dmesg-98926711.html
3. vmstat 1 10
vmstat 은 virtual memory stat 의 약어이다.
vmstat 은 아래와 같은 정보를 보여준다.
- procs
- r : run queue. 작업 수행을 위해 CPU 자원을 process 의 수. 아래 이미지의 ready
r 항목이 많으면 많을수록, CPU 를 사용하기 위한 process 의 수가 많다는 것을 의미.
즉, OS 자체의 bottleneck 이 존재함을 의미함 - b : blocked queue. 메모리 혹은 IO 응답을 기다리며 blocked 된 process 의 수. 아래 이미지의 waiting
- w : swap-out 되는 process 의 수. 이 값이 증가는 memory 가 굉장히 부족하다는 것을 의미함
- r : run queue. 작업 수행을 위해 CPU 자원을 process 의 수. 아래 이미지의 ready
procs 는 아래 그림을 보면 아 이거구나 라고 느낌이 팍 오...면 좋겠따 ㅎㅎ

- memory : memory 정보. 단위는 4KB. free -m 명령어를 통해서 같은 내용을 볼 수 있음
- swpd : 사용중인 swap memory 의 크기
- free : OS 가 사용 가능한 memory의 크기. 즉 현재 사용하지 않는, 여유 memory 공간의 크기
만약 숫자가 352000 이 떴다면, 352000 * 4KB = 1.408 GB 정도의 여유 memory 를 의미함 - buff : buffer 로 사용중인 memory 의 크기
- cache : cache 로 사용중인 memory 의 크기
buff 에 대해 더 자세히 찾아봄.
buffer 는 임시저장소 같은 느낌의 공간임
예를 들어 file write 를 진행할 때, 내용을 곧바로 file 로 저장하지 않고 이 buffer 에 일단 담아두고,
나중에 CPU 가 여유가 좀 생길 때 이 buffer 에 담아두었던 내용을 file 에 write 한다고 함
데이터 처리를 위한 임시공간이라는 점에서 cache 와 공통점이 있지만,
cache 와는 다르게 buffer는 한 번만 사용됨
cache 에 대한 설명은 여기 링크 참고.
- swap : memory swap 정보. 단위는 KB/s
- si : swap-in 된 메모리의 양. 즉, disk 에서 memory 로 swap-in 하는 양
disk 내 swap 공간에 있는 데이터를 memory 로 호출 - so : swap-out 된 메모리의 양. 즉, memory 에서 disk 로 swap-out 하는 양
memory 가 부족하기 때문에 swap-out 이 발생하여 disk 로 memory 의 데이터를 보냄
이 값이 높으면 memory 점검을 해봐야 함.
- si : swap-in 된 메모리의 양. 즉, disk 에서 memory 로 swap-in 하는 양
- io : disk IO. 단위는 blocks/s
- bi : 초당 블록 디바이스로 보내는 블록의 수
- bo : 초당 블록 디바이스로부터 받는 블록의 수
여기서 말하는 '블록 디바이스'란, 하드디스크, CD, DVD 등 블록이나 섹터 등의 단위로 데이터를 전송하는 장치를 의미함.
(블록 디바이스와는 다르게, byte 단위로 데이터를 전송하는 장치를 캐릭터 디바이스라고 함)
즉 bi,bo 는 disk IO 를 의미한다고 보면 됨
- system : system call 및 interrupt 정보
- in : 초당 interrupt 되는 양. time clock 과 ethernet 의 패킷도 포함되기 때문에
interrupt 수가 이상하게 많다면 네트워크 쪽을 점검해볼 필요가 있다고 함. - sy : system call. 초당 OS 의 시스템 영역에서 수행하는 system call 의 개수
process 가 OS 의 도움을 받아야 하는 작업(file IO 등)을 수행할 때 sy 의 수가 늘어날 것임 - cs : context switch. 초당 CPU 내에서 Process 간 Context 정보를 교체하는 횟수
CPU 를 사용하는 process 가 많을수록 cs 의 값이 증가할 것임
process 간 CPU 를 차지하기 위한 경쟁치.. 로 생각해도 될 듯.
- in : 초당 interrupt 되는 양. time clock 과 ethernet 의 패킷도 포함되기 때문에
위에서 설명하는 sy, cs 가 OS 의 bottleneck 을 의미하는 명확한 값은 아님
- cpu : cpu 사용률
- us : user CPU. 사용자 영역에서 사용하는 CPU 비율
- sy : system CPU. system call 에 의해 사용되는 CPU 비율
- id : idle CPU. 사용가능한 CPU 비율. 일반적으로 100-(us+sy)=id 로 계산된다고 함
이 값이 높을수록 CPU 가 놀고 있다고(....) 보면 됨 - wa : wait IO. IO 등의 작업으로 인해 대기중인 CPU 비율
- st : stolen time. hypervisor 가 가상 CPU 를 서비스하는 동안 실제 CPU 를 차지하는 시간
CPU 점유율이 높다고 할 때 us 의 비율이 높은지, sy 의 비율이 높은지 vmstat 으로 확인할 수 있다.
us 의 비율이 높은 이유는 일반적인 OS 명령어를 통해 알기 어렵지만,
sy 의 비율이 높은 이유는 truss 명령을 통해 알 수 있다고.
turss 명령을 통해 어떤 system call 이 수행중인지 확인 가능하다고 함.
vmstat의 명령어 가장 첫번째 줄은 이전의 vmstat 명령어로 수집된 정도에 대한 평균치를 나타냄.
즉, 현재의 정보가 아닌 이전에 누적된 정보임
따라서 현재 정보를 봐야 한다면 두번째 줄부터 보면 됨!
vmstat -s 옵션을 주어 시스템 부팅 이후 얼마나 많은 system events 가 발생했는지 볼 수 있다.
vmstat 1 10 처럼 뒤에 있는 숫자는 "1초마다 갱신되는 정보를 총 10번 보여주세요" 라는 의미임
만약 vmstat 2 라고 하면 2초마다 정보를 영원히 갱신하며 보여줌
vmstat 3 7 이라고 하면 3초마다 갱신되는 정보를 7번 보여줌
참고
buffer cache 설명 tldp.org/LDP/sag/html/buffer-cache.html
blog.naver.com/mybrainz/150099033294
4. mpstat -P ALL 1
mpstat 은 per-processor statistics 의 약어이다.
앞에 m은 multi-processor, multiple-processors, microprocessor, machine, monitor..
이 중 하나의 의미인 것 같으나 뭔지는 모르겠음. [관련 설명 링크]
mpstat 은 사용 가능한 CPU 와 Core 의 사용률을 나타낸다.
별다른 옵션 없이 mpstat 만 적용하면 전체 CPU 에 대한 사용률 통계치가 나온다.
mpstat -P 0 옵션을 넣으면 0번 (첫번째) CPU 에 대한 사용률 통계치가 나온다.
mpstat -P 1 옵션을 넣으면 1번 (두번째) CPU 에 대한 사용률 통계치가 나온다.
mpstat -P ALL 옵션을 넣으면 모든 CPU 에 대한 사용률 통계치가 나온다.
mpstat -P ALL 1 옵션을 넣으면 모든 CPU 에 대한 사용률 통계치가 1초마다 갱신되며 나온다.
mpstat 1 5 옵션을 넣으면 모든 CPU 에 대한 사용률 통계치가 1초마다 갱신되며 나오는데 총 5번 갱신한다.
mpstat 으로 나타나는 아래 정보들은 특정 CPU 사용 시간에 대한 백분률을 보여준다.
- 20시 23분 58초 : mpstat 을 수행한 시간
- CPU : CPU 번호. ALL, 1, 2, 3,, 등으로 나타난다.
- %usr : user level(application) process 를 구동하는데 사용된 CPU 사용률
- %nice : nice 우선순위가 적용된 user level(application) process 를 구동하는데 사용된 CPU 사용률
NI 값(nice 값)이 1~19 사이인 user process 에 의해 사용되는 CPU 사용률 - %sys : system level(kernel) process 를 구동하는데 사용된 CPU 사용률
- %iowait : IO 처리를 위해 기다리는 CPU 대기율(IO wait 동안의 CPU 대기율)
- %irq : Hardware interrupt 를 처리하기 위해 사용된 CPU 사용률
- %soft : Software interrupt 를 처리하기 위해 사용된 CPU 사용률
- %steal : 하이퍼바이저가 다른 가상 프로세서를 서비스하는 동안 vCPU 가 실제 CPU를 기다리는 시간의 백분율
VM(Virtual Machine) 등에서 동작하는 CPU 가 물리 머신으로부터 CPU 자원을 할당받기 위해
얼마나 대기하고 있는지 알 수 있음 - %guest : 하이퍼바이저 등에서 가상머신을 구동하는 경우,
이 가상 머신의 vCPU(virtual CPU) 를 구동하는데 사용된 CPU 사용률
이 때 가상머신은 nice 값이 적용되지 않은 가상 머신을 의미함 - %gnice : 하이퍼바이저 등에서 가상머신을 구동하는 경우,
이 가상 머신의 vCPU(virtual CPU) 를 구동하는데 사용된 CPU 사용률
이 때 가상머신은 nice 값이 적용된 가상 머신을 의미함 - %idle : CPU 가 유휴상태로 보내는 시간의 백분률. 즉 놀고 있는 CPU 백분률
위에서 말하는 'nice 우선순위' 라는 것은 CPU 스케줄링 우선순위를 의미함
nice 우선순위는 +19 ~ -20 의 숫자값을 갖는데, 숫자가 낮을수록 우선 순위가 높음.
nice 명령어로 프로세스 우선순위를 부여할 수 있고, renice 명령어로 우선 순위를 재조정할 수 있음
이 때 super user 권한이 필요함.
자세한 내용은 여기 참고
mpstat 명령어를 통해 전체 cpu 가 얼마나 일하고 있는지 알 수 있다.
하나의 cpu 만 동작하고 있다면, CPU 를 사용하는 application 이 single thread 로 동작한다는 뜻이 된다.
참고
linoxide.com/linux-command/linux-mpstat-command/
ssup2.github.io/command_tool/mpstat/
interp.blog/entry/프로세서의-우선순위-값-nice
5. pidstat 1 10
pidstat 은 process 의 UID, PID, 그리고 CPU 사용률을 보여준다.
Command 부분에서 프로세스의 이름을 알 수 있고, 해당 프로세스가 얼마만큼의 CPU 를 사용하고 있는지 알 수 있다.
top 명령어와 수행하는 것이 비슷하지만, top 처럼 전체 스크린을 띄우지 않고 그때 그때 출력을 해준다.
pidstat 으로 출력되는 내부 정보는 바로 위에 mpstat 부분을 참고
pidstat 1 10 처럼 뒤에 있는 숫자는 "1초마다 갱신되는 정보를 총 10번 보여주세요" 라는 의미임
만약 pidstat 2 라고 하면 2초마다 정보를 영원히 갱신하며 보여줌
pidstat 3 7 이라고 하면 3초마다 갱신되는 정보를 7번 보여줌
6. iostat 1 10
avg-cpu : CPU 정보를 보여줌
내용은 위에 4. mpstat 부분 참고
tps : 디스크 장치에서 초당 처리한 입출력 작업 개수
kB_read/s : 디스크 장치에서 초당 읽은 데이터 블록 수
kB_wrtn/s : 디스크 장치에서 초당 쓴 데이터 블록 수
kB_dscd/s : 디스크 장치에서 초당 삭제한 데이터 블록 수
kB_read : 디스크 장치에서 읽은 데이터 블록 수
kB_wrtn : 디스크 장치에서 쓴 데이터 블록 수
kB_dscd/s : 디스크 장치에서 삭제한 데이터 블록 수
r/s : 초당 완료된 read 요청 수
w/s : 초당 완료된 write 요청 수
r/s, w/s 등을 통해 어떤 요청이 들어오는지 보자.
과도한 요청에 의해 성능 문제가 생기는 경우가 있다고 함.
아래와 같은 옵션을 줄 수 있다.
iostat -c : cpu 정보를 출력
iostat -d : 디스크 장치의 입출력 정보를 출력
iostat -p /dev/장치명 : 지정된 디스크 장치의 정보를 출력
iostat -t : 결과값 앞에 시간을 포함하여 출력
iostat -n : NFS의 사용량을 출력 단, 커널 2.6.16이상부터 사용가능
iostat -k : 초당 블럭 수 대신 초당 Kb로 출력 단, 커널 2.6.16이상부터 사용가능
iostat -m : 초당 블럭 수 대신 초당 Mb로 출력 단, 커널 2.6.16이상부터 사용가능
iostat -x : 보다 확장된 통계 정보를 출력 -n과 -p옵션과 중복사용이 불가능함
iostat [숫자] : 숫자에 해당하는 초 만큼 출력값을 갱신
iostat 1 10 처럼 뒤에 있는 숫자는 "1초마다 갱신되는 정보를 총 10번 보여주세요" 라는 의미임
만약 iostat 2 라고 하면 2초마다 정보를 영원히 갱신하며 보여줌
iostat 3 7 이라고 하면 3초마다 갱신되는 정보를 7번 보여줌
참고
docs.oracle.com/cd/E24846_01/html/E23088/spmonitor-4.html
-x 옵션으로 나타나는 확장된 통계 정보 설명 m.blog.naver.com/bumsukoh/221022044759
7. free -hw
free 명령어는 시스템에서 사용중인 메모리 및 유휴 메모리의 정보를 보여준다.
- total
- Mem total : 시스템에 설치된 전체 메모리 크기
- Swap total : 설정된 swap 영역 크기
- used
- Mem used : 현재 사용중인 메모리 크기. total 에서 free, buff, cache 를 뺀 크기
- Swap used : 현재 사용중인 swap 영역 크기
이 크기가 계속 늘어난다면 메모리가 계속 부족하다는 의미이므로, 시스템 점검을 해봐야 함.
- free
- Mem free : 현재 유휴 메모리 크기. total 에서 used, buff, cache 를 뺀 크기
- Swap free : 사용되지 않는 swap 영역 크기
- shared : 여러 프로세스에서 사용할 수 있는 공유 메모리 크기. 프로세스 혹은 threads 간 통신에 사용됨
tmpfs(메모리 파일 시스템), ramfs 등으로 사용되는 공간 - buffers : 버퍼로 사용중인 메모리 크기
- cache : cache (그리고 slab) 로 사용중인 메모리 크기
- buff/cache : buffers 와 cache 의 합
- available : swapping 없이 새로운 프로세스에게 할당 가능한 메모리의 예상 크기
free 뒤에 붙을 수 있는 옵션에 대해 설명한다.
- [-h] : 사람이 읽기 쉬운 단위로 출력한다.
- [-b | -k | -m | -g] : 바이트, 키비바이트, 메비바이트, 기비바이트 단위로 출력한다.
- [--tebi | --pebi] : 테비바이트, 페비바이트 단위로 출력한다.
- [--kilo | --mega | --giga | --tera | --peta] : 킬로바이트, 메가바이트, 기기바이트, 페타바이트 단위로 출력한다.
- [-w] : 와이드 모드로 cache와 buffers를 따로 출력한다.
- [-c '반복'] : 지정한 반복 횟수 만큼 free를 연속해서 실행한다.
- [-s '초'] : 지정한 초 만큼 딜레이를 두고 지속적으로 실행한다.
- [-t] : 합계(Memory + Swap)가 계산된 total 을 추가로 출력한다.
리눅스는 항상 여유 메모리 공간(유휴 공간)을 Buffer와 Cache로 사용한다고 함.
따라서 cache 메모리도 유휴 메모리(여유 메모리)로 보아야 함.
메모리에 데이터를 저장(caching)해서 느린 디스크 IO 를 최대한 줄여 성능 향상을 하기 위함
Buffer는 디바이스 블록에 대한 메타데이터들을 메모리에 저장하는 곳임
블록 디바이스로부터 데이터를 읽어오기 위해 필요한 정보들을 메모리에 저장함.
Cache는 페이지 캐시와 slab으로 사용중인 메모리 공간임
페이지 캐시는 간단히 말해, 한 번 디스크에서 읽은 데이터를 메모리에 저장(caching)하고,
다음에 똑같은 데이터를 다시 읽을 때 디스크로 요청 대신 cache 에서 바로 읽어 성능을 향상시킴.
페이지 단위로 관리하기 때문에 페이지 캐시라고 함.
slab은 커널에서 관리하는 커널 오브젝트를 저장하는 단위임
커널은 어플리케이션 할당 단위(페이지)보다 작은 단위인 slab 단위로 메모리를 사용한다고 함.
하나의 메모리 페이지에 여러 slab들이 존재할 수 있음.
slab에 파일의 inode 이나 dentry 정보(파일의 자료구조를 나타내는 정보)들을 캐싱 가능하다고 함.
추가 정보는 여기 링크 참고
참고
zetawiki.com/wiki/리눅스_명목메모리사용률,_실질메모리사용률
https://www.linuxatemyram.com/
8. sar -n DEV 1
sar 은 System Activity Report 의 약어이다.
sar 명령어는 현재 리눅스 시스템의 cpu, memory, network, disk IO 등의 지표 정보를 수집하고 보여준다.
시스템의 다양한 활동을 모니터링 할 수 있는 명령어임.
sar -n DEV 명령어는 네트워크 장치의 통계치를 보여준다.
rx 는 received (inbound traffic), 즉 전송받음(수신) 을 의미하고
tx 는 transmitted (outbound traffic), 즉 전송보냄(송신) 을 의미한다.
- IFACE : Network Interface 이름
- rxpck/s : 초당 전송받은 패킷수
- txpck/s : 초당 전송보낸 패킷수
- rxbyt/s : 초당 전송받은 bytes 크기
- txbyt/s : 초당 전송보낸 bytes 크기
- rxcmp/s : 압축된 패킷을 초당 전송받은 수
- txcmp/s : 압축된 패킷을 초당 전송보낸 수
- rxmcst/s : 초당 전송받은 다중 패킷 (multicast) 수
- %ifutil : NIC 에서 사용 가능한 network 대역폭의 지표 0% = idle, 100 % = 최대치 (1G NIC 의 경우 1G 사용시)...
뭔 말인지 모르겠음
참고
sar 에 대한 자세한 설명
blog.naver.com/luckan7/10037958551
여태까지 명령어 중 제일 광범위한 정보를 포함하고 있어서, 내 입장에서 제일 사용하기 어려울 것 같음...
9. top
top 명령어는 리눅스 시스템의 전반적인 상황을 모니터링하는 툴이다.
더불어 프로세스 관리도 할 수 있다.
top 화면 상단의 1 user, 2 user,,, 는 현재 시스템에 접속해있는 사용자 수를 의미한다.
top 화면 상단의 load average 는 평균 부하율을 의미함. 위에 1.uptime 의 설명 참고.
- PID : 프로세스 ID (PID) 각 프로세스마다 고유한 PID 를 갖는다.
- USER : 프로세스를 실행시킨 사용자 ID
- PR : 프로세스의 우선순위 (priority)
- NI : NICE 값. 일의 nice value값이다. nice value 가 적을수록 우선순위가 높음.
- VIRT : process 가 사용중인 가상 메모리(Virtual Memory) 크기. SWAP+RES. 단위는 KiB
- RES : process 가 사용중인 물리 메모리 크기(Resident Size). 단위는 KiB
- SHR : 다른 process 들과 공유하는 공유 메모리(Shared Memory)의 크기. 단위는 KiB
- S : 프로세스의 상태 [ S(sleeping), R(running), W(swapped out process), Z(zombies), I(idle) ]
- %CPU : 프로세스가 사용하는 CPU의 사용율
- %MEM : 프로세스가 사용하는 메모리의 사용율
- TIME+ : 프로세스 시작된 이후 경과된 총 시간
- COMMAND : 실행된 명령어
아래 단축키를 사용하여 여러 기능을 수행할 수 있다.
- shift + t : 실행된 시간이 큰 순서로 정렬
- shift + m : 메모리 사용량이 큰 순서로 정렬
- shift + p : cpu 사용량이 큰 순서로 정렬
- k : Process 종료
- k 입력 후 종료할 PID를 입력
- signal을 입력하라 표시되면 9를 넣어줌
- 'kill -9 PID' 명령어와 같음!
- c : 명령 인자 표시 / 비표시
- l(소문자엘) : uptime line(첫번째 행)을 표시 / 비표시
- space bar : Refresh
- u : 입력한 유저 소유의 Process만 표시
- which user : 와 같이 유저를 입력하라 표시될때 User를 입력
- blank(공백) 입력시 모두 표시
- shift + b : 상단의 uptime 및 기타 정보값을 블락선택해 표시
- f : 화면에 표시될 프로세스 관련 항목 설정
- i : idle 또는 좀비 상태의 프로세스는 표시 되지 않음
- z : 출력 색상 변경
- d [sec] : 설정된 초단위로 Refresh
- c : command뒤에 인자값 표시
- q : 명령어 종료
- 1 : CPU core 별로 cpu 정보를 표시
화면이 주기적으로 갱신되어 보기 힘든 경우도 있는데, 멈추려면 아래 단축키를 사용한다.
Ctrl+S 는 업데이트를 중지하고, Ctrl+Q 는 업데이트를 다시 시작한다.
top -p [PID] 명령어를 통해, 내가 원하는 PID 하나의 정보만 볼 수 있다.
top 명령어보다 보기 쉬운 htop 을 사용하는 것이 정신건강에 이로울 것 같다.
참고
www.cubrid.com/tutorial/3794195
zzsza.github.io/development/2018/07/18/linux-top/
추가)
ps 명령어 결과를 정렬하여 볼 수 있다.
cpu 를 많이 사용하는 순으로 정렬하여 보는 방법은 아래와 같다.
| ps aux --sort -%cpu | head -n 6 ps -eo comm,pcpu --sort -pcpu | head -5 |
memory 를 많이 사용하는 순으로 정렬하여 보는 방법은 아래와 같다.
| ps aux --sort -%mem | head -n 6 ps -eo comm,pmem --sort -pmem | head -5 |
참고
https://www.networkworld.com/article/3596800/how-to-sort-ps-output.html
기타 참고 자료
https://brunch.co.kr/@lars/9#comment
https://eyeballs.tistory.com/484
1-1 : sysstat 소개
1-2 : sysstat 설치
1-3 : sar 란?
1-4 : sar 설정
1-5 : sar 옵션
1-6 : sar 실전 활용
1-1 sysstat 소개
- sysstat 이란?
리눅스 성능 측정 도구 패키지입니다.
해당 패키지에는 아래와 같은 성능 분석 툴을 제공합니다. sar을 사용하기 위해선 sysstat 설치합니다.
+ sar : cpu, memory, network, diks io 등 지표를 수치화하며 파일로 저장.
+ iostat : disk io에 지표 측정
+ mpstat : cpu 지표 측정
+ tapestat : tape 드라이버의 IO 지표 측정
+ pidstat : 특정 프로세스의 CPU 및 스레드 정보 지표 측정
+ cifsiostat : cifs 파일 시스템 지표 측정
이 중 실제로 많이 쓰이는 툴은 sar, iostat입니다.
iostat 은 따로 정리된 브런치가 있으며, 해당 브런치에선 sar에 대해서 정리합니다.
1-2 sysstat 설치
설치 방법은 repo를 통한 yum 또는 apt로 간단하게 설치할 수 있다.
하지만 최신 버전의 sysstat 은 rpm, deb 파일로 설치할 수 있고, rpm, deb를 제공하지 않는 버전의 경우 컴파일해서 설치할 수 있다. 설치 방법에 대해선 이미 많은 자료가 있으므로 생략한다.
이 글은 CentOS 7.5 + sysstat 12.1.3 rpm 설치 작성했다.
+ sysstat 공식 다운로드 링크에서 최신 버전의 rpm을 다운로드한다.
+ sysstat 구버전이 설치되어 있다면 삭제해야 한다. rpm -qa | grep sysstat으로 확인할 수 있으며,
rpm -e 옵션 또는 yum erase sysstat으로 구 버전 삭제을 진행한다. (삭제 시 기존의 sar 데이터 파일들이 삭제되므로 백업이 필요하면 미리 해놓자!)
+ 다운로드 한 최신 버전의 sysstat을 아래와 같이 rpm 설치를 진행한다.

+ /etc/init.d/sysstat start # sysstat 데몬을 시작합니다. 이후 systemd를 통한 제어도 가능합니다.
여기까지가 rpm을 통한 sysstat-12.1.3 버전 설치 끝입니다.
package install (2020.03 추가)
- 2020년3월 기준 stable version 최신 버전 12.2.1 download link : http://sebastien.godard.pagesperso-orange.fr/download.html
- centos 7.x & ubuntu 18.04 기준으로 재설치 테스트 후 기록을 남김. OS별로 설치 환경별로 sysstat 경로가 살짝 다를수 있으니 참고하여 진행 한다.
- 기존에 설치된 sysstat 을 깨끗하게 삭제 해야 한다.
+ systemctl stop sysstat.service
+ centos : rpm -e sysstat-버전기입(rpm -qa | grep sysstat 으로 확인 가능)
+ ubuntu : dpkg --purge sysstat
- 다운로드한 12.2.1 폴더에 들어가서 아래와 같이 설치
+ ./configure && make && make install
+ ./configure -h 로 여러가지 기능 옵션도 지원하니 확인 해봐도 좋다.
- systemd 등록 : 아래와 같이 systemd 서비스 파일을 생성 한다.
## Centos 인 경우
vi /usr/lib/systemd/system/sysstat.service
[Unit] Description=Resets System Activity Logs
[Service]
Type=oneshot
RemainAfterExit=yes
User=root
ExecStart=/usr/local/lib64/sa/sa1 --boot
[Install] WantedBy=multi-user.target
## ubuntu 인 경우
vi /lib/systemd/system/sysstat.service
[Unit]
Description=Resets System Activity Logs
[Service]
Type=oneshot
RemainAfterExit=yes
User=root
ExecStart=/usr/local/lib/sa/sa1 --boot
[Install] WantedBy=multi-user.target
- sar cron (1초 마다 수집) 등록
+ /etc/cron.d/ 밑에 sysstat 관련 파일이 있으면 삭제 하고, /etc/cron.d/sysstat 파일로 생성해보자.
## centos 의 경우 설정
* * * * * root /usr/local/lib64/sa/sa1 1 60
# 00 00 * * * root /usr/local/lib64/sa/sa2 -A # <== 이건 선택사항
## ubuntu 의 경우 설정
* * * * * root /usr/local/lib/sa/sa1 1 60
# 00 00 * * * root /usr/local/lib/sa/sa2 -A # <== 이건 선택사항
- conf 파일 설정
+ 혹시나 sysstat 서비스을 올렸다가 내려 놓는다. (systemctl stop sysstat.service)
+ /var/log/sa 경로의 파일 중 금일 날자의 파일을 삭제 한다. (삭제 할 경우 해당 날자의 sar date 가 날라감)
+ /etc/sysconfig/sysstat 설정 파일에서 SADC_OPTIONS="-S XALL" 와 같이 전체 데이터 수집으로 변경 (이건 각자 설정에 맞게 진행)
+ 서비스 시작 ( systemctl start sysstat.service )
- color 설정 추가
+ /etc/profile 에 아래와 같이 추가
export S_COLORS="auto"
LANG=C
- rhel, centos 의 경우 development versions 최신 버전에선 rpm 으로 제공 한다. 하지만 커널 버전별로 에러가 Dependency(의존성) 에러가 날수 있으니, sysstat download 파일 중 src.rpm 파일로 빌드 해서 업데이트 하면 깔끔하다. 빌드하는 방법은 간략하게 아래와 같이 진행한다.
+ rpm -ivh sysstat-12.3.1-1.src.rpm
+ 설치 하면 home 폴더 밑에 rpmbuild 폴더가 생성 되며, 여기서 SPECS 폴더로 이동
+ rpmbuild -ba 생성된spec파일
+ rpmbuild 폴더 밑에 RPMS 폴더가 생성되고 여기에 빌드된 rpm으로 업데이트 진행
+ 해당 방법은 기존 sysstat 삭제 및 설정을 별도로 안해도 된다.
1-3 sar 란?
- sar (systecm activity reporter)
리눅스 시스템의 cpu, memory, network, disk io 등의 지표 정보를 수집하여 sar command을 통해 실시간으로 지표를 보여 주며, 파일로 저장한다. sar을 구성하는 요소는 아래와 같다.
(1) sadc : system activity data collector
지표 데이터를 collect 하며 이를 /var/log/sa/sa~ 형태의 이진 데이터 파일로 저장하는 도구입니다.
(2) sadf : Display data collected by sar in multiple formats
지표 데이터 파일은 이진 파일 형식이라 sar 로만 report 할 수 있다. sadf는 csv, xml, svg 등의 포맷으로 변환해주는 도구이다. 주로 sar의 데이터를 다른 모니터링 리소스 지표의 데이터로 활용할 때 쓰이며, 최신 버전에선 svg 포맷으로 웹페이지에서 GUI 형식으로도 볼 수 있다.
(3) sa1 : Collect and store binary data in the system activity daily data file
sadc로 추출한 모든 지표 데이터를 /var/log/sa날자 파일에 바이너리 형식으로 저장하는 bash 스크립트.
(4) sa2 : Create a report from the current standard system activity daily data file
s1으로 생성된 데이터 파일을 기반으로, 원하는 지표 옵션을 선택해 사람이 읽을 수 있는 파일 형태로 1벌 더 저장 (/var/log/sar날자 파일) 하는 bash 스크립트.
(sa1으로 추출한 데이터만으로도 분석이 가능하여, 굳이 sa2를 사용할 필요는 없다. 디스크 용량만 잡아먹고... 그냥 이런 기능이구나 정도만 알자.)
sysstat 설치 후 기본 옵션의 경우 지표 주기는 10분에 1번씩 수집하고, disk io에 대한 옵션을 쓰지 못하도록 되어 있다.
sar의 목적은 시스템에 어떤 구간에 영향이 있는지 분석하기 위한 툴로써, 1초 주기로 데이터 파일을 저장, disk io 옵션도 자주 사용되므로 활성화시키는 게 좋다.
(1) sar 지표 옵션 수정 및 로그 저장 일자 설정
/etc/sysconfig/sysstat
=> 적용시점 : 수정 후 sysstat을 재시작해야 적용되며, SADC_OPTIONS의 경우 기존 파일(금일 날자)이 아닌 다음날 신규 데이터 파일부터 적용된다. (즉시 적용하려면 금일 날자의 saDD 파일을 삭제하면, 적용된 시점 시간부터 적용된다.)

+ HISTORY : sa2 의 sar 파일의 보관 일자 설정 항목. 1초 데이터로 설정했을 경우 sar 파일당 크기가 1 ~ 2GB 정도 됩니다. Disk size를 고려해서 일자 선택을 하시면 됩니다.
+ + HISTORY 에 설정한 일정은 sa2 를 실행하는 당시의 기준이므로, cron으로 설정된 sysstat 에 sa2를 활성화 해야 적용 됩니다.
+ SADC_OPTIONS : sadc의 지표 옵션을 선택하는 부분입니다. 아무것도 안 넣으면 기본 지표만 수집합니다. disk io에 대한 항목은 기본 항목에 없으므로, "-S XDISK" 옵션을 추가합니다.
"-S XALL" 전체 옵션의 경우 전체 지표를 출력합니다. (XALL의 경우 로그 사이즈가 커지고, 제 기준에선 아직까지(현재 sysstat 버전) 중요도가 낮은 지표라 판단됨)
sadc 추가 옵션이 종류는 아래와 같습니다.
++ POWER [sar -m 키워드] : Report power management statistics로 CPU 전압 상태, 서버 온도 등의 지표를 추출합니다. (현재 까진 미흡하여 좀 더 sysstat 버전업 되고 써야 될 듯 함...)
++ SNMP [sar -n 키워드] : network 지표 중 icmp, ip, tcp 등의 지표를 추출.
++ INT [sar -I 키워드] : interrupts 지표 추출
++ DISK : [sar -d] : disk io 지표 추출
++ XDISK : [sar-d, sar -F] : disk io 및 파일 시스템 지표 추출
++ XALL : 전체 지표 수집
+ 기타 설정 : CentOS의 경우 그 외 압축 관련된 옵션이 있으나 기본으로 쓰셔도 무방 하며, Ubuntu의 경우 /etc/default/syssat 에 ENABLED="true" 활성화를 추가로 해주시고, 파일 경로가 centos와 다르게 /etc/sysstat/sysstat 에 있으니 참고하세요.
(2) sar 지표 수집 주기 설정
/etc/cron.d/sysstat
=> 적용 시점 : 즉시 적용 (crond 재시작 필요 없음)

+ sa1 : 기본 설정은 10분에 1번 수집하여 파일로 저장하도록 설정된다. 예를 들면
01:00:00
01:10:00
01:20:00
위와 같이 당시 시점의 지표를 찍는다. (10분 동안의 평균값이 아닌 시점 값을 찍음)
정확한 서버 분석을 위해선 지표 단위를 1초로 설정하길 권장한다. (로그 파일 사이즈가 커질 수 있으니 참고)
(ex.1) * */10 * * * root /usr/lib64/sa/sa1 1 1
=> [10분마다 / 1초 간격 / 1번] 10분에 간격의 지표를 추출해 /var/log/sa 날자 파일로 저장한다.
(ex.2) * * * * * root /usr/lib64/sa/sa1 1 1
=> [1분마다 / 1초 간격 / 1번] 1분 간격의 지표를 추출해 /var/log/sa 날자 파일로 저장한다.
(ex.3) * * * * * root /usr/lib64/sa/sa1 1 60 # <== 1초 마다 수집 (권장)
=> [1분마다 / 1초 간격 / 60번] 1초 간격의 지표를 추출해 /var/log/sa 날자 파일로 저장한다.
+ sa2 : 기본 설정은 매일 23:53분에 sarDD 형식의 파일로 사람이 읽을 수 있는 형식으로 한벌 더 저장한다.
sar -f /var/log/sa/saDD 커멘드로 충분히 지표 분석이 가능하므로, 굳이 disk 용량만 차지하는 sa2 설정은 주석 처리하길 권장한다. (추가 수정 : HISTORY 로그 보관 주기 적용을 위해 적용하길 권장)
sa2 는 /etc/cron.d/sysstat (ubuntu의 경우 /etc/cron.daily/sysstat 추가확인) 에 매일 한번씩 돌게 설정 되어 있다. 파일 크기를 줄일려면 sa2 -A 가 아닌 다른 옵션을 주면 되고, HISTORY 로그 보관 설정을 적용하기 위해선 활성화 한다.
(ex.1) 53 23 * * * root /usr/lib64/sa/sa2 -A
=> 매일 23:53분에 sar -A 옵션의 내용을 /var/log/sar 날자 파일로 저장한다.
(ex.2) 53 12 * * * root /usr/lib64/sa/sa2 -q
=> 매일 12:53분에 sar -q 옵션의 내용을 /var/log/sar날자 파일로 저장한다.
- centos (rocky) 8, 9 버전, ubuntu 22.04 설정
centos (rocky) 8 이상 ubuntu 22.04 이상 부터 systemd timer 를 사용하도록 변경되었다.
아래 2가지 설정을 적용하고 systemctl daemon-reload 하면 된다.
1) /lib/systemd/system/sysstat-collect.timer
[Timer] <== Timer 기존 설정 지우고 아래 항목으로 변경
OnCalendar=
OnCalendar=*:*:0/1 <== 1초 설정
AccuracySec=500ms
2) /lib/systemd/system/sysstat-collect.service
[Unit]
StartLimitIntervalSec=1 <== 이 구문 추가
systemctl daemon-reload 를 한후 위에 설정한 인터벌에 적용 된다.
+ 인터벌 1분 : OnCalendar=*:0/1
+ 인터벌 10초 : OnCalendar=*:*:0/10
+ 인터벌 1초 : OnCalendar=*:*:0/1
sar 옵션
(1) -u [기본 옵션] + [ALL] : CPU utilization


+ %user : 사용자 레벨(application level)에서 실행 중일 때의 CPU 사용률
+ %nice : 사용자 레벨(appliaction level)에서 nice 가중치를 준 CPU 사용률
+ %system : 시스템 레벨(kernel)에서 실행 중인 CPU 사용률
+ %iowait : Disk I/O 처리가 늦어서 프로세스가 idle 상태가 되는 비율
+ %steal : virtual processer에 의한 작업이 진행되는 동안 virtual CPU에 의해 뜻하지 않는 대기시간이 생기는 시간의 비율
+ %idle : CPU의 idle 상태의 비율 (disk I/O는 제외된 지표)
-- 아래는 ALL 옵션에 나오는 항목
+ %usr : %user 은 virtual processer 가 포함된 지표이고, %usr 은 virtual processer 가 제외된 지표.
+ %sys : %system 은 H/W S/W 인터럽트가 포함된 지표이고, %sys 는 인터럽트가 제외된 지표
+ %irq : H/W 인터럽트 사용률
+ %soft : S/W 인터럽트 사용률
+ %guest : virtual processor 사용률
+ %gnice : virtual processor에서 nice 가중치를 준 사용률
(2) -d : block device

+ DEV : disk device 종류를 뜻 한다. lsblk 나 /proc/partitions을 참조하면, disk device 영역을 알 수 있다.


+ tps : 초당 I/O 전체 IOPS
+ rkB/s : 초당 disk에 read 된 kbyte 크기. (ex. 1024kB/s == 초당 1MB을 disk read 했다.)
+ wrB/s : 초당 disk에 write 된 kbyte 크기. (ex. 2048kB/s == 초당 2MB을 disk write 했다.)
+ dkB/s : 초당 disk에 discard 된 크기.
+ areq-sz : 해당 Device에 발생된 request의 평균 size ( 1 == 1kb )
+ aqu-sz : 해당 Device에 발생된 request들의 queue의 평균 length ( request 평균 size의 대기열이 수량, 즉 보통 1 이하 일 경우 바로바로 처리된다는 거고, 1이 넘어가는 시점부터 queue에 쌓여서 부하 지표를 산출함)
+ await : 발생된 io의 평균 처리 시간(ms) (보통 1ms 이하로 나와야 정상이며, 1ms 이상이 나올 경우는 squ-sz length 가 늘어나면서 한계치에 근접하거나 넘었다고 판단)
+ %util : 디스크의 idle 한계치 지표 ( 100% == 한계치 이상 부하 진행 중)
==> raid cache 나 nand 제품같이 뒷단에 parallel 처리 (디스크 또는 nand 수만큼의 분산처리)를 하는 제품에선 %util 의 한계치를 측정할 수 없다.
(3) -b : I/O and transfer rate statistics

+ tps : 초당 전송 양이며, IOPS 값으로 보면 된다. (ex. 4k 섹터로 100 tps = 초당 400kb)
+ rtps : 읽기(read) iops
+ wtps : 쓰기(write) iops
+ dtps : discard iops
+ bread/s : 초당 읽은 (read) 블록 수 (blockdev --getbsz /dev/sda4로 블록을 확인하고, 만약 512 block 크기에 bread/s 가 100이면 5120byte 입니다.)
+ bwrtn/s : 초당 쓰여진 (write) 블록 수
+ bdscd/s : 초당 discard 된 블록 수

ex)
+ 22303 tps : 4kb 블록을 초당 22303번 disk I/O 발생.
+ 22303 wtps : 4kb 블록을 초당 22303번 write I/O 발생 ( 4096byte x 22303 = 91MB/s)
+ 178424 bwrtn/s : 초당 178424번의 block을 쓰고 있다. (해당 disk는 512b 일 경우, 178424 x 512b = 91,353,088byte (91MB))
(4) -q : load averages queue length

+ runq-sz : 실행을 위해 CPU를 대기 중인 메모리의 커널 스레드 수입니다. 일반적으로 이 값은 2보다 작아야 합니다. 지속적으로 높은 값은 시스템이 CPU 제한적임을 나타냅니다.
+ plist-sz : 프로세스 목록에서 프로세스와 스레드의 개수를 나타낸다.
+ ldavg-1 : 1분간의 시스템의 Load Average 값을 나타낸다.
+ ldavg-5 : 5분간의 시스템의 Load Average 값을 나타낸다.
+ ldavg-15 : 15분간의 시스템의 Load Average 값을 나타낸다.
+ blocked : 현재 돌고 있는 io job 수 (waiting for I/O to complete). (예를 들어 dd로 write 하는 커멘드를 5개를 동시에 날리면 해당 지표가 5가 되고, 이중 3개가 완료되면 2가 된다.)
(5) -r [ALL] : memory utilization statistics


( )의 명칭은 /proc/meminfo 항목과 동일한 명칭이다.
+ kbmemfree (MemFree) : free 상태의 메모리 크기
+ kbavail (MemAvailable) : swap 없이 새로운 프로세스를 시작할 때 사용할 수 있는 메모리 양
+ kbmemused (MemTotal - (MemFree + Buffers + Cached + Slab): user 영역에서 사용 중인 메모리 크기
+ %memused : 사용 중인 메모리의 점유 백분율
+ kbbuffers (Buffers) : buffer cache 메모리 크기
+ kbcached (Cached) : page cache 메모리 크기
+ kbcommit (Committed_AS) : 현재 시스템에 할당된 메모리의 크기. (실제 사용 중인 user영역 크기 + cache 인 듯하다.) 현재의 워크로드(Workload)상에서 어느 정도의 RAM 또는 SWAP 이 더 필요할지를 예측하여 Out of memory가 발생하지 않을 만한 메모리 양이다.
+ %commit : kbcommit의 점유 백분율
+ kbactive (Active) : 사용 중인 메모리에서 (LRU list), 최근에 사용된 메모리 정보이며, 메모리 부족으로 여유 메모리를 확보 (reclaiming) 할 때 후순위의 크기이다. (반환을 되도록 안 하는 크기)
+ kbinact (Inactive) : 사용 중인 메모리에서 (LRU list) 최근에 사용되지 않은 영역의 크기며, 메모리 확보 시 즉시 반환 가능한 크기
+ kbdirty (Dirty) : disk에 write 하기 위해 대기 중인 크기
+ kbanonpg (AnonPages) : user 영역 페이지 테이블에 매핑되는 non-file 지원 page 크기
+ kbslab (Slab) : 커널 내 자료구조 캐시
+ kbkstack (KernelStack) : 커널 스택이 사용하는 메모리. (이건 회수 안됨)
+ kbpgtbl (PageTables) : page table 크기. 시스템의 모든 page를 기록하기 위한 메모리 크기이며, 많은 프로세스가 동일한 공유 메모리 세그먼트에 연결되어 있으면이 값이 커질 수 있습니다.
+ kbvmused (VmallocUsed) : 사용된 vmalloc 영역의 크기
(6) -B : paging statistics

kswapd과 메모리 할당 관련 자세한 정보는 아래 브런치 글에 정리 잘 되어 있으니 참조하세요.
https://brunch.co.kr/@alden/14
+ pgpgin/s : 초당 page in (KB/s) 된 크기
+ pgpgout/s : 초당 page out (KB/s) 된 크기
+ fault/s : page fault (minor + major) 수 즉 새로운 메모리 요청 시 발생 (memory 메커니즘을 공부 필요)
++ minor : page fault 후 reclaim 요청을 받을 때 메모리에 새로 할당받는 요청
++ major : swap out 된 Disk에 page 접근 요청이 있을 경우, disk => memory로 swap in (IO가 발생) 되는 요청
+ majflt/s : major 되는 횟수 (디스크 => 메모리 page을 이동하여 IO 가 발생) swap 된 경우 빈번.
+ pgfree/s : free page의 초당 개수
+ pgscank/s : kswapd가 page scan 한 횟수로 메모리가 부족할 경우 (kswapd을 활성화되는 순간) 발생 (swap을 쓰기 위하거나, page cahe 정리를 할 때 발생)
+ pgscand/s : kernel에서 page scan 한 횟수
+ pgsteal/s : 메모리 요구를 충족하기 위해 시스템이 초당 캐시(페이지 캐시 및 스왑 캐시)에서 재 확보한 페이지 수입니다.
+ %vmeff : kswapd가 스캔한 페이지 중 릴리즈 (disk write) 된 비율 (%)
(7) -H : hugepages utilization statistics

( )의 명칭은 /proc/meminfo 항목과 동일한 명칭이다.
+ kbhugfree (HugePages_Free) : allocated 되지 않은 hugepage 크기 (kb)
+ kbhugused : allocated 된 hugepage 크기 (kb).
+ %hugused (HugePages_Total) : allocated 된 hugepage % 백분율
+ kbhugrsvd (HugePages_Rsvd) : reserved 된 hugepage 크기 (kb)
+ kbhugsurp (HugePages_Surp) : surplus 된 hugepage 크기 (kb)
- hugepage (THP) 보충 설명

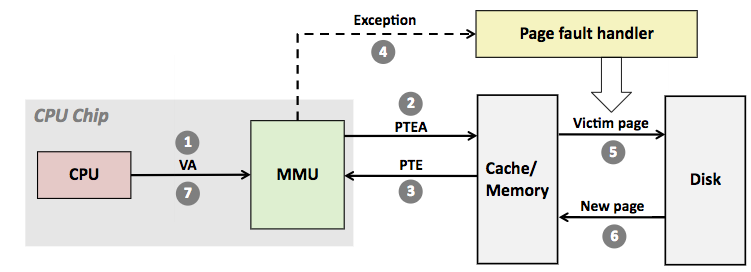
1. CPU가 VA (virtual address)을 MMU (Memory Management Unit)을 통해 TLB에 해당 주소가 있는지 찾는다.
2. 있다면 바로 메모리의 해당 영역의 데이터를 가져온다.
3. 만약 없다면, 메모리의 TTB (Translation Table Base Address)에 주소를 찾아 TLB에 넣어주고, 다시 메모리에 요청해서 데이터를 가져온다.
이 구조의 문제는 TLB로 hit 가 안 될 경우 느리다는 것이다. 메모리는 빠르지만 CPU에 비하면 느리다.
TLB는 CPU 내부에 있고 용량이 매우 적다.
보통 4KB 크기의 page table 이 많아지면 (메모리 크기는 점점 증가 추세) 그만큼 TLB entry가 커지게 됩니다. 즉 TLB hit 율이 떨어지게 됩니다.
해결 방법은 TLB entry을 줄이는 것이고, 줄이기 위해선 THP (Transparent Huge Pages)을 이용해 기존의 4KB page table 대신 그 이상의 크기로 page을 동적으로 할당하여 사용하는 기능을 쓴다.

THP로 구글링 하면 많이 나오지만 해당 기능이 오히려 문제가 되는 케이스가 종종 있다. disable 쓰는 걸 권장합니다.

만약 THP disable 시 아래와 같이 hughpage 값이 0이 됩니다. 즉 sar -H 내용에 볼 게 없습니다.

(8) -W : swapping statistics

+ pswpin/s : 초당 swap in 횟수
+ pswpout/s : 초당 swap out 횟수
해당 지표가 올라가면 disk io가 높아지므로 서버 퍼포먼스의 문제가 될 수 있다.
(9) -S : swap space utilization statistics

+ kbswpfree : free swap 크기(kb)
+ kbswpused : 사용 중인 swap 크기(kbytes)
+ %swpused : 사용 중이 swap %
+ kbswpcad : cache 된 swap 크기
+ %swpcad : cache 된 swap %
(10) -F : statistics for currently mounted filesystems

+ MBfsfree : free 디스크 크기 (MB)
+ MBfsused : 사용 중인 디스크 크기 (MB)
+ %fsused : 사용 중인 디스크 백분율 %
+ %ufsused : free 디스크 백분율 %
+ Ifree : free inode 수
+ Iused : 사용 중인 inode 수
+ %Iused : 사용 중인 inode 백분율 %
+ FILESYSTEM : 파티션 영역
(11) -v : status of inode, file and other kernel tables.

+ dentunusd : dentry cache 중 사용하지 않는 반환 가능한 dentry cache 개수
==> 해당 지표가 갑자기 떨어지면, 메모리가 모자라서 (vm.vfs_cache_pressure 커널 설정 등) 반환하는 작업과 함께 부하가 올 수 있다.
+ file-nr : open file 수 = (cat /proc/sys/fs/file-nr)
==> open file 부족으로 인한 이슈일 때 참고 하자.
+ inode-nr : open inode 수 = (cat /proc/sys/fs/inode-nr)
+ pty-nr : pty(pseudo-terminals) handles의 수, ssh, telnet, xterm shell 접속된 수
강제로 cache 정리
+ echo 1 > /proc/sys/vm/drop_caches ## page cache 비우기
+ echo 2 > /proc/sys/vm/drop_caches ## dentries, inode 비우기
+ echo 3 > /proc/sys/vm/drop_caches ## page, dentries, inode 모두 비우기
(12) -n [ALL] : network statistics.
-n 네트워크는 다양한 옵션을 제공합니다. 이 중 주로 보게 되는 옵션만 설명합니다.
해당 항목은 필히 TCP/IP 개념을 숙지하셔야 이해 하기 수월 합니다.
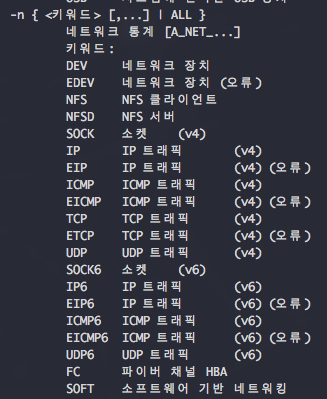

- rx : received 수신 (inbound traffic)
- tx : transmitted 송신 (outbount traffic)
+ IFACE : network interface 명
+ rxpck/s : 초당 rx 수
+ txpck/s : 초당 tx 수
+ rxkB/s : 초당 rx 된 크기 (kb)
+ txkB/s : 초당 tx 된 크기 (kb)
+ rxcmp/s : 초당 압축된 패킷의 rx 수
+ txcmp/s : 초당 압축된 패킷의 tx 수
+ rxmcst/s : 초당 rx 된 다중 패킷 (multicast) 수
+ %ifutil : NIC에서 사용 가능한 network 대역폭의 지표 0% = idle, 100% = 최대치(1G NIC의 경우 1G 사용 시)

+ IFACE : network interface 명
+ rxerr/s : 초당 error rx 수
+ txerr/s : 초당 error tx 수
+ coll/s : 초당 발생한 패킷 충돌 수
+ rxdrop/s : OS buffer 부족으로 rx drop 된 수
+ txdrop/s : OS buffer 부족으로 tx drop 된 수
==> ethtool -g eth0으로 ring 값을 확인 하자. ring값을 변경하는 이유는 대량의 데이터로 인하여 packet이 dorpped 되거나 discard 되는 경우가 있다.
+ txcarr/s : 패킷 tx 중 발생한 초당 carrier-errors 수
+ rxfram/s : 패킷 rx 중 발생한 초당 frame alignment 수
+ rxfifo/s : 패킷 rx 중 발생한 초당 FIFO overrun error 수
+ txfifo/s : 패킷 tx 중 발생한 초당 FIFO overrun error 수

+ totsck : 총 사용된 socket 수
==> 65000개 이상 발생 시 더 이상 소켓 생성이 안되어 문제가 될 수 있음
+ tcpsck : 현재 사용 중인 TCP 소켓 수
==> 해당 지표가 최대치로 올라갈 경우 net.ipv4.ip_local_port_range 커널 값에 설정된 값과 비교하여 디버깅
+ udpsck : 현재 사용 중인 UDP 소켓 수
+ rawsck : 현재 사용 중인 RAW socket 수
+ ip-frag : 현재 queue에 IP fragments 수
+ tcp-tw : TIME_WAIT 상태의 소켓 수

https://loicpefferkorn.net/2018/09/linux-network-statistics-reference/#ip
아래 내용부터는 [ ] 표시의 값은 위 링크를 참조하세요.
+ irec/s : rx 된 datagrams 수 [ipInReceives]
+ fwddgm/s : 최종 목적지로 가기 위해 포당 forward 된 수 [netstat -s의 ipForwDatagrams]
+ idel/s : irec/s 중 성공적으로 (ICMP포함) rx 된 수 [ipOutRequests]
+ orq/s : tx 된 datagrams 수 [ipInReceives]
+ asmrq/s : fragments received 된 rx 수[ipReasmReqds]
+ asmok/s : datagrams이 성공적으로 re-assembled 된 수 [ipReasmOKs]
+ fragok/s : 성공적으로 fragmented 된 수 [ipFragOKs]
+ fragcrt/s : datagrams fragments 생성된 수 [ipFragCreates]

+ ihdrerr/s : 잘못된 체크섬, 버전 불일치, 시간 초과, IP 옵션 처리 시 오류 등으로 버려진 datagrams 수 [ipInHdrErrors]
+ iadrerr/s : IP 헤더의 목적지 필드에 있는 IP가 수신할 유효한 주소가 아니어서 버려진 datagrams 수[ipInAddrErrors]
+ iukwnpr/s : 지원되지 않는 프로토콜로 인해 수신은 성공했지만 무시된 datagrams 수 [ipInUnknownProtos]
+ idisc/s : 리눅스 nic 버퍼 공간 부족 등으로 버려진 rx ip datagrams 수 [ipInDiscards]
+ odisc/s : 리눅스 nic 버퍼 공간 부족 등으로 버려진 tx ip datagrams 수[ipOutDiscards]
+ onort/s : 목적지 경로를 찾을 수 없어 버려진 ip datagrams 수 [ipOutNoRoutes]
+ asmf/s : IP re-assembly algorithm 의해 감지된 실패된 datagrams 수 [ipReasmFails]
+ fragf/s : Fragment flag 설정으로 Fragment로 인해 버려진 datagrams 수 [ipFragFails]

+ active/s : CLOSED ==> SYN-SENT 상태로 전환한 수 [tcpActiveOpens]
+ passive/s : LISTEN ==> SYN-RCVD 상태로 전환한 수 [TcpPassiveOpens]
+ iseg/s : rx 된 총 세그먼트 수 [tcpInSegs]
+ oseg/s : tx 된 총 세그먼트 수 [tcpOutSegs]

+ atmptf/s : SYN-SEND or SYN-RCVD ==> CLOSED or LISTEN 전환한 수 [tcpAttemptFails]
+ estres/s : ESTABLISHED or CLOSE-WAIT ==> CLOSED 전환한 수 [tcpEstabResets]
+ retrans/s : 재전송된 세그먼트 수 [tcpRetransSegs]
+ isegerr/s : 오류로 rx 된 세그먼트 수 [tcpInErrs]
+ orsts/s :오류로 tx 된 세그먼트 수 [tcpOutRsts]

+ total/s : 초당 처리된 network frames processe 수
+ dropd/s : processing queue 부족으로 drop 된 network frames 수
+ squeezd/s : 초당 softirq handler function 종류 된 수
+ rx_rps/s : 프로세스 간에 패킷 처리를 위해 인터럽트로 woken up 된 수
+ flw_lim/s : 초당 flow limit 도달 한 수. CPU의 패킷 처리 부하 분산을 위해 flow 제한하여 제어한 횟수
==> flow limit 참조 : https://blog.packagecloud.io/eng/2016/06/22/monitoring-tuning-linux-networking-stack-receiving-data/#flow-limits
(13) -w : task creation and system switching activity.
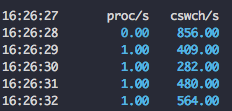
+ proc/s : 초당 생성된 tasks 수
+ cswch/s : 초당 context switches 수
1-6 sar 실전 활용
서버에 대한 이슈를 트레킹 할 수 있는 최소한의 도구는 sar이다. 보통 설치 시 기본 설치되어 있으며 (가능하면 최신 버전을 권장) 반드시 기본 설정이 아닌 위에 제시한 1초 간격의 설정을 하고, disk 용량이 적다면 최소 3~7일 정도로 sar file을 보관하도록 하자. 이게 전제 조건이 되어야 이슈 파악이 가능합니다.
Q. 3일 전 19:30 분 경에 db 서버 한대가 slow 쿼리가 갑자기 늘었는데 왜 그런가요?
A. 3일 전의 지표를 분석하기 위해 아래와 같이 이슈가 난 시간대의 모든 지표를 불러와 서 특이점을 찾습니다.
sar -f /var/log/sa/sa23 -A -s 19:20:00 -e 19:40:00 --human ## 19:20 ~ 19:40 사이의 모든 지표를 본다 (--human 옵션은 byte, kb, mb, gb 등 단위를 보기 편하게 자동 변환해주는 옵션)
19:30 지표에 다른 시간과 다른 뭔가 튀거나 줄어든 지표가 있는지 확인하고, 해당 지표에 대해 분석한다.
+ 하드웨어 disk 장애 : 완전 장애가 아닌 bad sector 카운트가 올라가면서 순간 io가 멈추는 경우가 있다. sar -d 옵션에서 ioutil이나 await 항목을 확인한다.
+ swap 사용 : 메모리 부족으로 swap을 사용하게 되면 disk io가 부하가 걸리게 된다. sar -W -S을 확인.
+ 그 회에도 local port 부족이나 open file 부족 등 다양한 원인이 있을 수 있으나, sar로 모두 확인 가능하다.
Q. sar 지표 보기가 너무 어려운데, GUI나 좀 더 보기 편하게 보는 방법은 없을까요?
A. 최신 12 버전에선 svg 형식의 GUI 파일을 전환하여 볼 수 있습니다.
sadf -T -g /var/log/sa/sa23 -- -A > gui_sar.svg
위와 같은 커멘드로 svg 파일로 변환 후 웹브라우저를 통해 GUI 환경으로 볼 수 있습니다.
하지만 변환하는 시간이 길고, 오히려 문제 있는 시간만 추출해 cli로 보는 게 저는 더 편한 거 같습니다.
GUI로 보려면 sar data를 기반으로 오픈소스 기반 모니터링 툴을 연동해서 보시면 됩니다.
예제로 모니터링 대상 서버에 netdata 설치하고 prometheus 나 kafak 로 지표 데이터 파싱 해서 grafana 로 필요 항목만 커스텀하게 보실 수 있습니다.

추가로 로컬 시간 표시와 sar cli에서 수치별로 color 가 변경되는 건, profile이나. bash_profile 등에
export S_COLORS="auto"
LANG=C
을 추가하시면 됩니다.
- kSar 툴을 통한 확인
kSar git page : https://github.com/vlsi/ksar
아래 jar 파일을 다운 받아서 실행 합니다.
+ download : https://github.com/vlsi/ksar/releases/download/v5.2.3/ksar-5.2.3-all.jar

- Data - Load from a file 선택 후 파일을 불러 옵니다.
+ sar 는 아래와 같은 형식으로 추출 후 kSar 에서 열어 주면 됩니다.
LANG=C sar -A > /tmp/sar.txt
+ 아래와 같이 GUI로 확인 가능 합니다.
sar.txt file 크기가 100MB 넘으면 kSar 가 먹통이 되는거 같습니다.
이 외에도 sar2html 은 web port 열어서 웹을 통해 확인 가능하고 docker와 kubernetes 로 말아서 올릴수 있도록 이미지도 제공 하네요.
이런 비슷한 툴이 몇몇 있습니다.
추천 드리진 않습니다. gui 로 이쁘게 보실꺼면 다른 모니터링 솔루션을 설치해서 보세요~
그냥 이렇게 볼수 있구나 정도로만 참고 하고 CLI로 분석 하는게 더 편한거 같습니다.

해당 글은 틀린 정보나 추가할 정보가 있을 때 수정 및 추가될 예정입니다.
마지막으로 해당 글은 옵션을 항상 외우지 못해서, 제가 가끔 보려고 만든 글이라
두서없고 오탈자도 있고, 틀린 정보가 있을 수 있으며, 구글링 하면 sysstat과 그 외 지표 분석 글이 많으니... 참고해주세요~
* * * * * root /usr/local/lib64/sa/sa1 1 60
'ㆍ Linux' 카테고리의 다른 글
| coredump, 세그먼트 폴트, segfault at 0 ip error 4 in libc-2.28.so (0) | 2023.08.09 |
|---|---|
| rtkit, RealtimeKit, rtkit-daemon, 실시간 정책 및 Watchdog 데몬 (0) | 2023.07.20 |
| CentOS 7, Pacemaker, 클러스터 (0) | 2023.07.06 |
| 리눅스 시스템 모니터링 시스템 최적화 (0) | 2023.06.23 |
| sar 명령어를 이용한 시스템 모니터링, LINUX (0) | 2023.06.20 |